The pseudo-marginal approach to MCMC for Bayesian inference
In a previous post I described a generalisation of the Metropolis Hastings MCMC algorithm which uses unbiased Monte Carlo estimates of likelihood in the acceptance ratio, but is nevertheless exact, when considered as a pseudo-marginal approach to “exact approximate” MCMC. To be useful in the context of Bayesian inference, we need to be able to compute unbiased estimates of the (marginal) likelihood of the data given some proposed model parameters with any “latent variables” integrated out.
To be more precise, consider a model for data  with parameters
with parameters  of the form
of the form 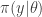 together with a prior on ,
together with a prior on ,  , giving a joint model
, giving a joint model

Suppose now that interest is in the posterior distribution

We can construct a fairly generic (marginal) MCMC scheme for this posterior by first proposing  from some fairly arbitrary proposal distribution and then accepting the value with probability
from some fairly arbitrary proposal distribution and then accepting the value with probability 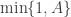 where
where
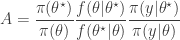
This method is great provided that the (marginal) likelihood of the data is available to us analytically, but in many (most) interesting models it is not. However, in the previous post I explained why substituting in a Monte Carlo estimate  will still lead to the exact posterior if the estimate is unbiased in the sense that
will still lead to the exact posterior if the estimate is unbiased in the sense that ![E[\hat\pi(y|\theta)]=\pi(y|\theta)](https://s0.wp.com/latex.php?latex=E%5B%5Chat%5Cpi%28y%7C%5Ctheta%29%5D%3D%5Cpi%28y%7C%5Ctheta%29&bg=ffffff&fg=333333&s=0&c=20201002) . Consequently, sources of (cheap) unbiased Monte Carlo estimates of (marginal) likelihood are of potential interest in the development of exact MCMC algorithms.
. Consequently, sources of (cheap) unbiased Monte Carlo estimates of (marginal) likelihood are of potential interest in the development of exact MCMC algorithms.
Latent variables and marginalisation
Often the reason that we cannot evaluate is that there are latent variables in the problem, and the model for the data is conditional on those latent variables. Explicitly, if we denote the latent variables by  , then the joint distribution for the model takes the form
, then the joint distribution for the model takes the form

Now since

there is a simple and obvious Monte Carlo strategy for estimating provided that we can evaluate  and simulate realisations from
and simulate realisations from 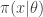 . That is, simulate values
. That is, simulate values 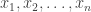 from for some suitably large
from for some suitably large  , and then put
, and then put
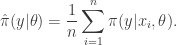
It is clear by the law of large numbers that this estimate will converge to as  . That is, is a consistent estimate of . However, a moment’s thought reveals that this estimate is not only consistent, but also unbiased, since each term in the sum has expectation . This simple Monte Carlo estimate of likelihood can therefore be substituted into a Metropolis-Hastings acceptance ratio without affecting the (marginal) target distribution of the Markov chain. Note that this estimate of marginal likelihood is sometimes referred to as the Rao-Blackwellised estimate, due to its connection with the Rao-Blackwell theorem.
. That is, is a consistent estimate of . However, a moment’s thought reveals that this estimate is not only consistent, but also unbiased, since each term in the sum has expectation . This simple Monte Carlo estimate of likelihood can therefore be substituted into a Metropolis-Hastings acceptance ratio without affecting the (marginal) target distribution of the Markov chain. Note that this estimate of marginal likelihood is sometimes referred to as the Rao-Blackwellised estimate, due to its connection with the Rao-Blackwell theorem.
Importance sampling
Suppose now that we cannot sample values directly from , but can sample instead from a distribution  having the same support as . We can then instead produce an importance sampling estimate for by noting that
having the same support as . We can then instead produce an importance sampling estimate for by noting that

Consequently, samples from can be used to construct the estimate

which again is clearly both consistent and unbiased. This estimate is often written

where 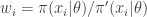 . The weights,
. The weights, 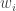 , are known as importance weights.
, are known as importance weights.
Importance resampling
An idea closely related to that of importance sampling is that of importance resampling where importance weights are used to resample a sample in order to equalise the weights, often prior to a further round of weighting and resampling. The basic idea is to generate an approximate sample from a target density 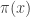 using values sampled from an auxiliary distribution
using values sampled from an auxiliary distribution 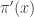 , where we now supress any dependence of the distributions on model parameters, .
, where we now supress any dependence of the distributions on model parameters, .
First generate a sample 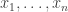 from and compute weights
from and compute weights  . Then compute normalised weights
. Then compute normalised weights 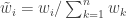 . Generate a new sample of size by sampling times with replacement from the original sample with the probability of choosing each value determined by its normalised weight.
. Generate a new sample of size by sampling times with replacement from the original sample with the probability of choosing each value determined by its normalised weight.
As an example, consider using a sample from the Cauchy distribution as an auxiliary distribution for approximately sampling standard normal random quantities. We can do this using a few lines of R as follows.
n=1000
xa=rcauchy(n)
w=dnorm(xa)/dcauchy(xa)
x=sample(xa,n,prob=w,replace=TRUE)
hist(x,30)
mean(w)
Note that we don’t actually need to compute the normalised weights, as the sample function will do this for us. Note also that the average weight will be close to one. It should be clear that the expected value of the weights will be exactly 1 when both the target and auxiliary densities are correctly normalised. Also note that the procedure can be used when one or both of the densities are not correctly normalised, since the weights will be normalised prior to sampling anyway. Note that in this case the expected weight will be the (ratio of) normalising constant(s), and so looking at the average weight will give an estimate of the normalising constant.
Note that the importance sampling procedure is approximate. Unlike a technique such as rejection sampling, which leads to samples having exactly the correct distribution, this is not the case here. Indeed, it is clear that in the 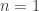 case, the final sample will be exactly drawn from the auxiliary and not the target. The procedure is asymptotic, in that it improves as the sample size increases, tending to the exact target as .
case, the final sample will be exactly drawn from the auxiliary and not the target. The procedure is asymptotic, in that it improves as the sample size increases, tending to the exact target as .
We can understand why importance resampling works by first considering the univariate case, using correctly normalised densities. Consider a very large number of particles,  . The proportion of the auxiliary samples falling in a small interval
. The proportion of the auxiliary samples falling in a small interval 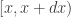 will be
will be 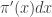 , corresponding to roughly
, corresponding to roughly 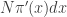 particles. The weight for each of those particles will be
particles. The weight for each of those particles will be  , and since the expected weight of a random particle is 1, the sum of all weights will be (roughly) , leading to normalised weights for the particles near of
, and since the expected weight of a random particle is 1, the sum of all weights will be (roughly) , leading to normalised weights for the particles near of ![\tilde{w}(x)=\pi(x)/[N\pi'(x)]](https://s0.wp.com/latex.php?latex=%5Ctilde%7Bw%7D%28x%29%3D%5Cpi%28x%29%2F%5BN%5Cpi%27%28x%29%5D&bg=ffffff&fg=333333&s=0&c=20201002) . The combined weight of all particles in is therefore
. The combined weight of all particles in is therefore  . Clearly then, when we resample times we expect to select roughly
. Clearly then, when we resample times we expect to select roughly  particles from this interval. This corresponds to a proportion
particles from this interval. This corresponds to a proportion  , corresponding to a density of in the final sample.
, corresponding to a density of in the final sample.
Obviously the above argument is very informal, but can be tightened up into a reasonably rigorous proof for the 1d case without too much effort, and the multivariate extension is also reasonably clear.
The bootstrap particle filter
The bootstrap particle filter is an iterative method for carrying out Bayesian inference for dynamic state space (partially observed Markov process) models, sometimes also known as hidden Markov models (HMMs). Here, an unobserved Markov process, 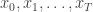 governed by a transition kernel
governed by a transition kernel  is partially observed via some measurement model
is partially observed via some measurement model 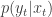 leading to data
leading to data  . The idea is to make inference for the hidden states
. The idea is to make inference for the hidden states  given the data
given the data 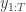 . The method is a very simple application of the importance resampling technique. At each time,
. The method is a very simple application of the importance resampling technique. At each time,  , we assume that we have a (approximate) sample from
, we assume that we have a (approximate) sample from 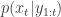 and use importance resampling to generate an approximate sample from
and use importance resampling to generate an approximate sample from 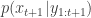 .
.
More precisely, the procedure is initialised with a sample from 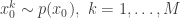 with uniform normalised weights
with uniform normalised weights 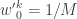 . Then suppose that we have a weighted sample
. Then suppose that we have a weighted sample  from . First generate an equally weighted sample by resampling with replacement
from . First generate an equally weighted sample by resampling with replacement  times to obtain
times to obtain 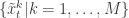 (giving an approximate random sample from ). Note that each sample is independently drawn from
(giving an approximate random sample from ). Note that each sample is independently drawn from  . Next propagate each particle forward according to the Markov process model by sampling
. Next propagate each particle forward according to the Markov process model by sampling  (giving an approximate random sample from
(giving an approximate random sample from  ). Then for each of the new particles, compute a weight
). Then for each of the new particles, compute a weight 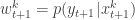 , and then a normalised weight
, and then a normalised weight  .
.
It is clear from our understanding of importance resampling that these weights are appropriate for representing a sample from , and so the particles and weights can be propagated forward to the next time point. It is also clear that the average weight at each time gives an estimate of the marginal likelihood of the current data point given the data so far. So we define
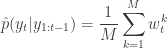
and

Again, from our understanding of importance resampling, it should be reasonably clear that  is a consistent estimator of
is a consistent estimator of  . It is much less clear, but nevertheless true that this estimator is also unbiased. The standard reference for this fact is Del Moral (2004), but this is a rather technical monograph. A much more accessible proof (for a very general particle filter) is given in Pitt et al (2011).
. It is much less clear, but nevertheless true that this estimator is also unbiased. The standard reference for this fact is Del Moral (2004), but this is a rather technical monograph. A much more accessible proof (for a very general particle filter) is given in Pitt et al (2011).
It should therefore be clear that if one is interested in developing MCMC algorithms for state space models, one can use a pseudo-marginal MCMC scheme, substituting in  from a bootstrap particle filter in place of
from a bootstrap particle filter in place of 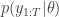 . This turns out to be a simple special case of the particle marginal Metropolis-Hastings (PMMH) algorithm described in Andreiu et al (2010). However, the PMMH algorithm in fact has the full joint posterior
. This turns out to be a simple special case of the particle marginal Metropolis-Hastings (PMMH) algorithm described in Andreiu et al (2010). However, the PMMH algorithm in fact has the full joint posterior 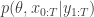 as its target. I will explain the PMMH algorithm in a subsequent post.
as its target. I will explain the PMMH algorithm in a subsequent post.

