Several papers have appeared recently discussing the issue of how to tune the number of particles used in the particle filter within a particle MCMC algorithm such as particle marginal Metropolis Hastings (PMMH). Three such papers are:
- Doucet, Arnaud, Michael Pitt, and Robert Kohn. Efficient implementation of Markov chain Monte Carlo when using an unbiased likelihood estimator. arXiv preprint arXiv:1210.1871 (2012).
- Pitt, Michael K., Ralph dos Santos Silva, Paolo Giordani, and Robert Kohn. On some properties of Markov chain Monte Carlo simulation methods based on the particle filter. Journal of Econometrics 171, no. 2 (2012): 134-151.
- Sherlock, Chris, Alexandre H. Thiery, Gareth O. Roberts, and Jeffrey S. Rosenthal. On the efficiency of pseudo-marginal random walk Metropolis algorithms. arXiv preprint arXiv:1309.7209 (2013).
I have discussed psuedo marginal MCMC and particle MCMC algorithms in previous posts. It will be useful to refer back to these posts if these topics are unfamiliar. Within particle MCMC algorithms (and psuedo-marginal MCMC algorithms, more generally), an unbiased estimate of marginal likelihood is constructed using a number of particles. The more particles that are used, the better the estimate of marginal likelihood is, and the resulting MCMC algorithm will behave more like a “real” marginal MCMC algorithm. For a small number of particles, the algorithm will still have exactly the correct target, but the noise in the unbiased estimator of marginal likelihood will lead to poor mixing of the MCMC chain. The idea is to use just enough particles to ensure that there isn’t “too much” noise in the unbiased estimator, but not to waste lots of time producing a super-accurate estimate of marginal likelihood if that isn’t necessary to ensure good mixing of the MCMC chain.
The papers above try to give theoretical justifications for certain “rules of thumb” that are commonly used in practice. One widely adopted scheme is to tune the number of particles so that the variance of the log of the estimate of marginal liklihood is around one. The obvious questions are “where?” and “why?”, and these questions turn out to be connected. As we will see, there isn’t really a good answer to the “where?” question, but what people usually do is use a pilot run to get an estimate of the posterior mean, or mode, or MLE, and then pick one and tune the noise variance at that particular parameter value. As to “why?”, well, the papers above make various (slightly different) assumptions, all of which lead to trading off mixing against computation time to obtain an “optimal” number of particles. They don’t all agree that the variance of the noise should be exactly 1, but they all agree to an order of magnitude.
All of the above papers make the assumption that the noise distribution associated with the marginal likelihood estimate is independent of the parameter at which it is being evaluated, which explains why there isn’t a really good answer to the “where?” question – under the assumption it doesn’t matter what parameter value is used for tuning – they are all the same! Easy. Except that’s quite a big assumption, so it would be nice to know that it is reasonable, and unfortunately it isn’t. Let’s look at an example to see what goes wrong.
Example
In Chapter 10 of my book I look in detail at constructing a PMMH algorithm for inferring the parameters of a discretely observed stochastic Lotka-Volterra model. I’ve stepped through the computational details in a previous post which you should refer back to for the necessary background. Following that post, we can construct a particle filter to return an unbiased estimate of marginal likelihood using the following R code (which relies on the smfsb CRAN package):
require(smfsb)
# data
data(LVdata)
data=as.timedData(LVnoise10)
noiseSD=10
# measurement error model
dataLik <- function(x,t,y,log=TRUE,...)
{
ll=sum(dnorm(y,x,noiseSD,log=TRUE))
if (log)
return(ll)
else
return(exp(ll))
}
# now define a sampler for the prior on the initial state
simx0 <- function(N,t0,...)
{
mat=cbind(rpois(N,50),rpois(N,100))
colnames(mat)=c("x1","x2")
mat
}
# construct particle filter
mLLik=pfMLLik(150,simx0,0,stepLVc,dataLik,data)
Again, see the relevant previous post for details. So now mLLik() is a function that will return the log of an unbiased estimate of marginal likelihood (based on 150 particles) given a parameter value at which to evaluate.
What we are currently wondering is whether the noise in the estimate is independent of the parameter at which it is evaluated. We can investigate this for this filter easily by looking at how the estimate varies as the first parameter (prey birth rate) varies. The following code computes a log likelihood estimate across a range of values and plots the result.
mLLik1=function(x){mLLik(th=c(th1=x,th2=0.005,th3=0.6))}
x=seq(0.7,1.3,length.out=5001)
y=sapply(x,mLLik1)
plot(x[y>-1e10],y[y>-1e10])
The resulting plot is as follows (click for full size):

So, looking at the plot, it is very clear that the noise variance certainly isn’t constant as the parameter varies – it varies substantially. Furthermore, the way in which it varies is “dangerous”, in that the noise is smallest in the vicinity of the MLE. So, if a parameter close to the MLE is chosen for tuning the number of particles, this will ensure that the noise is small close to the MLE, but not elsewhere in parameter space. This could have bad consequences for the mixing of the MCMC algorithm as it explores the tails of the posterior distribution.
So with the above in mind, how should one tune the number of particles in a pMCMC algorithm? I can’t give a general answer, but I can explain what I do. We can’t rely on theory, so a pragmatic approach is required. The above rule of thumb usually gives a good starting point for exploration. Then I just directly optimise ESS per CPU second of the pMCMC algorithm from pilot runs for varying numbers of particles (and other tuning parameters in the algorithm). ESS is “expected sample size”, which can be estimated using the effectiveSize() function in the coda CRAN package. Ugly and brutish, but it works…
 with parameters
with parameters  of the form
of the form 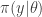 together with a prior on
together with a prior on  , giving a joint model
, giving a joint model 

 from some fairly arbitrary proposal distribution and then accepting the value with probability
from some fairly arbitrary proposal distribution and then accepting the value with probability 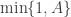 where
where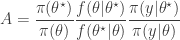
 will still lead to the exact posterior if the estimate is unbiased in the sense that
will still lead to the exact posterior if the estimate is unbiased in the sense that ![E[\hat\pi(y|\theta)]=\pi(y|\theta)](https://s0.wp.com/latex.php?latex=E%5B%5Chat%5Cpi%28y%7C%5Ctheta%29%5D%3D%5Cpi%28y%7C%5Ctheta%29&bg=ffffff&fg=333333&s=0&c=20201002) . Consequently, sources of (cheap) unbiased Monte Carlo estimates of (marginal) likelihood are of potential interest in the development of exact MCMC algorithms.
. Consequently, sources of (cheap) unbiased Monte Carlo estimates of (marginal) likelihood are of potential interest in the development of exact MCMC algorithms. , then the joint distribution for the model takes the form
, then the joint distribution for the model takes the form

 and simulate realisations from
and simulate realisations from 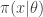 . That is, simulate values
. That is, simulate values 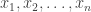 from
from  , and then put
, and then put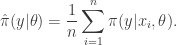
 . That is,
. That is,  having the same support as
having the same support as 


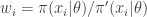 . The weights,
. The weights, 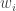 , are known as importance weights.
, are known as importance weights.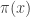 using values sampled from an auxiliary distribution
using values sampled from an auxiliary distribution 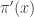 , where we now supress any dependence of the distributions on model parameters,
, where we now supress any dependence of the distributions on model parameters, 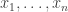 from
from  . Then compute normalised weights
. Then compute normalised weights 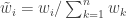 . Generate a new sample of size
. Generate a new sample of size 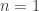 case, the final sample will be exactly drawn from the auxiliary and not the target. The procedure is asymptotic, in that it improves as the sample size increases, tending to the exact target as
case, the final sample will be exactly drawn from the auxiliary and not the target. The procedure is asymptotic, in that it improves as the sample size increases, tending to the exact target as  . The proportion of the auxiliary samples falling in a small interval
. The proportion of the auxiliary samples falling in a small interval 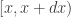 will be
will be 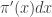 , corresponding to roughly
, corresponding to roughly 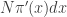 particles. The weight for each of those particles will be
particles. The weight for each of those particles will be  , and since the expected weight of a random particle is 1, the sum of all weights will be (roughly)
, and since the expected weight of a random particle is 1, the sum of all weights will be (roughly) ![\tilde{w}(x)=\pi(x)/[N\pi'(x)]](https://s0.wp.com/latex.php?latex=%5Ctilde%7Bw%7D%28x%29%3D%5Cpi%28x%29%2F%5BN%5Cpi%27%28x%29%5D&bg=ffffff&fg=333333&s=0&c=20201002) . The combined weight of all particles in
. The combined weight of all particles in  . Clearly then, when we resample
. Clearly then, when we resample  particles from this interval. This corresponds to a proportion
particles from this interval. This corresponds to a proportion  , corresponding to a density of
, corresponding to a density of 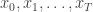 governed by a transition kernel
governed by a transition kernel  is partially observed via some measurement model
is partially observed via some measurement model 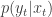 leading to data
leading to data  . The idea is to make inference for the hidden states
. The idea is to make inference for the hidden states  given the data
given the data 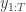 . The method is a very simple application of the importance resampling technique. At each time,
. The method is a very simple application of the importance resampling technique. At each time,  , we assume that we have a (approximate) sample from
, we assume that we have a (approximate) sample from 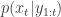 and use importance resampling to generate an approximate sample from
and use importance resampling to generate an approximate sample from 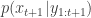 .
.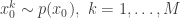 with uniform normalised weights
with uniform normalised weights 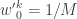 . Then suppose that we have a weighted sample
. Then suppose that we have a weighted sample  from
from  times to obtain
times to obtain 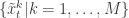 (giving an approximate random sample from
(giving an approximate random sample from  . Next propagate each particle forward according to the Markov process model by sampling
. Next propagate each particle forward according to the Markov process model by sampling  (giving an approximate random sample from
(giving an approximate random sample from  ). Then for each of the new particles, compute a weight
). Then for each of the new particles, compute a weight 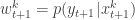 , and then a normalised weight
, and then a normalised weight  .
. 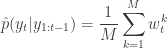

 is a consistent estimator of
is a consistent estimator of  . It is much less clear, but nevertheless true that this estimator is also unbiased. The standard reference for this fact is
. It is much less clear, but nevertheless true that this estimator is also unbiased. The standard reference for this fact is  from a bootstrap particle filter in place of
from a bootstrap particle filter in place of 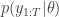 . This turns out to be a simple special case of the particle marginal Metropolis-Hastings (PMMH) algorithm described in
. This turns out to be a simple special case of the particle marginal Metropolis-Hastings (PMMH) algorithm described in 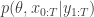 as its target. I will explain the PMMH algorithm in a subsequent post.
as its target. I will explain the PMMH algorithm in a subsequent post.