Motivation and background
In this post I will try and explain an important idea behind some recent developments in MCMC theory. First, let me give some motivation. Suppose you are trying to implement a Metropolis-Hastings algorithm, as discussed in a previous post (required reading!), but a key likelihood term needed for the acceptance ratio is difficult to evaluate (most likely it is a marginal likelihood of some sort). If it is possible to obtain a Monte-Carlo estimate for that likelihood term (which it sometimes is, for example, using importance sampling), one could obviously just plug it in to the acceptance ratio and hope for the best. What is not at all obvious is that if your Monte-Carlo estimate satisfies some fairly weak property then the equilibrium distribution of the Markov chain will remain exactly as it would be if the exact likelihood had been available. Furthermore, it is exact even if the Monte-Carlo estimate is very noisy and imprecise (though the mixing of the chain will be poorer in this case). This is the “exact approximate” pseudo-marginal MCMC approach. To give credit where it is due, the idea was first introduced by Mark Beaumont in Beaumont (2003), where he was using an importance sampling based approximate likelihood in the context of a statistical genetics example. This was later picked up by Christophe Andrieu and Gareth Roberts, who studied the technical properties of the approach in Andrieu and Roberts (2009). The idea is turning out to be useful in several contexts, and in particular, underpins the interesting new Particle MCMC algorithms of Andrieu et al (2010), which I will discuss in a future post. I’ve heard Mark, Christophe, Gareth and probably others present this concept, but this post is most strongly inspired by a talk that Christophe gave at the IMS 2010 meeting in Gothenburg this summer.
The pseudo-marginal Metropolis-Hastings algorithm
Let’s focus on the simplest version of the problem, where we want to sample from a target 
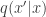

Here we are assuming that 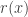

but it is not immediately clear that in many cases this will lead to the Markov chain having an equilibrium distribution that is exactly 

Put 
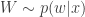
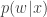
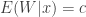



The key to understanding the pseudo-marginal approach is to realise that at each iteration of the MCMC algorithm a new value of 

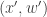
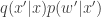
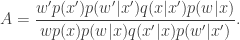
Inspection of this acceptance ratio reveals that the target of the chain must be (proportional to)
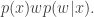
This is a joint density for 
Examples
We will consider again the example from the previous post – simulation of a chain with a N(0,1) target using uniform innovations. Using R, the main MCMC loop takes the form
pmmcmc<-function(n=1000,alpha=0.5)
{
vec=vector("numeric", n)
x=0
oldlik=noisydnorm(x)
vec[1]=x
for (i in 2:n) {
innov=runif(1,-alpha,alpha)
can=x+innov
lik=noisydnorm(can)
aprob=lik/oldlik
u=runif(1)
if (u < aprob) {
x=can
oldlik=lik
}
vec[i]=x
}
vec
}
Here we are assuming that we are unable to compute dnorm exactly, but instead only a Monte-Carlo estimate called noisydnorm. We can start with the following implementation
noisydnorm<-function(z)
{
dnorm(z)*rexp(1,1)
}
Each time this function is called, it will return a non-negative random quantity whose expectation is dnorm(z). We can now run this code as follows.
plot.mcmc<-function(mcmc.out)
{
op=par(mfrow=c(2,2))
plot(ts(mcmc.out),col=2)
hist(mcmc.out,30,col=3)
qqnorm(mcmc.out,col=4)
abline(0,1,col=2)
acf(mcmc.out,col=2,lag.max=100)
par(op)
}
metrop.out<-pmmcmc(10000,1)
plot.mcmc(metrop.out)

So we see that we have exactly the right N(0,1) target, despite using the (very) noisy noisydnorm function in place of the dnorm function. This noisy likelihood function is clearly unbiased. However, as already discussed, a constant bias in the noise is also acceptable, as the following function shows.
noisydnorm<-function(z)
{
dnorm(z)*rexp(1,2)
}
Re-running the code with this function also leads to the correct equilibrium distribution for the chain. However, it really does matter that the bias is independent of the state of the chain, as the following function shows.
noisydnorm<-function(z)
{
dnorm(z)*rexp(1,0.1+10*z*z)
}
Running with this function leads to the wrong equilibrium. However, it is OK for the distribution of the noise to depend on the state, as long as its expectation does not. The following function illustrates this.
noisydnorm<-function(z)
{
dnorm(z)*rgamma(1,0.1+10*z*z,0.1+10*z*z)
}
This works just fine. So far we have been assuming that our noisy likelihood estimates are non-negative. This is clearly desirable, as otherwise we could wind up with negative Metropolis-Hasting ratios. However, as long as we are careful about exactly what we mean, even this non-negativity condition may be relaxed. The following function illustrates the point.
noisydnorm<-function(z)
{
dnorm(z)*rnorm(1,1)
}
Despite the fact that this function will often produce negative values, the equilibrium distribution of the chain still seems to be correct! An even more spectacular example follows.
noisydnorm<-function(z)
{
dnorm(z)*rnorm(1,0)
}
Astonishingly, this one works too, despite having an expected value of zero! However, the following doesn’t work, even though it too has a constant expectation of zero.
noisydnorm<-function(z)
{
dnorm(z)*rnorm(1,0,0.1+10*z*z)
}
I don’t have time to explain exactly what is going on here, so the precise details are left as an exercise for the reader. Suffice to say that the key requirement is that it is the distribution of W conditioned to be non-negative which must have the constant bias property – something clearly violated by the final noisydnorm example.
Before finishing this post, it is worth re-emphasising the issue of re-using old Monte-Carlo estimates. The following function will not work (exactly), though in the case of good Monte-Carlo estimates will often work tolerably well.
approxmcmc<-function(n=1000,alpha=0.5)
{
vec=vector("numeric", n)
x=0
vec[1]=x
for (i in 2:n) {
innov=runif(1,-alpha,alpha)
can=x+innov
lik=noisydnorm(can)
oldlik=noisydnorm(x)
aprob=lik/oldlik
u=runif(1)
if (u < aprob) {
x=can
}
vec[i]=x
}
vec
}
In a subsequent post I will show how these ideas can be put into practice in the context of a Bayesian inference example.

Hello,
First of all much thanks Darren for this blog post. The ideas you explain here are nice and relevant to my present research. However, I still don’t fully understand how we obtain the expression for approximate acceptance ratio. Here is what I tried to do, to the best of my understanding:
acc_ratio = P(x’, w’)*q(x|x’)*P(w|x)/[P(x, w)*q(x’|x)*P(w’|x’)]
= P(w’|x’)*P(x’)*q(x|x’)*P(w|x)/[P(w|x)*P(x)*q(x’|x)*P(w’|x’)], using fact that P(x,w) = P(w|x)*P(x).
But I am stuck at this point. I couldn’t obtain the exact expression you mentioned in the post. By the way, my above attempt is based on the view you mentioned that the mcmc chain must be viewed as joint update to both x and w. Any help is appreciated.
Regards,
Kshitij Judah
I’ve had a couple of queries of this nature, so my explanation is obviously not sufficiently clear. The point really is that rather than thinking about what acceptance probability you would “need” in order to get things to work the way you want, you actually just think about the “approximate” acceptance probability, treat that as a given, and then wonder what equilibrium distribution this “approximate” acceptance ratio must target. Once you have introduced the auxiliary variable W, you can write down what the proposal density is, and then factor this out of the acceptance ratio to get the ratio of target densities. From this ratio of target densities it is clear that the target density is p(x)wp(w|x), and it is clear from the unbiasedness property that this has the desired marginal for x.
Hello,
Yes, I am able to derive it now, thanks!!
Hello,
I also wanted to ask you whether you know of any work that generalizes the setting considered in this post. This is the setting I am talking about:
In the setting I am considering, I need to sample from a probability distribution P(x) proportional to exp(a*V(x)) (a is just a constant), where V(x) is an expected value of some function g of some random variable z, whose distribution is parametrized by x. So V(x) = E[g(z) | x], where z is distributed according to some distribution P(z|x).
However, it is also the case that computing V(x) = E[g(z) | x] is computationally infeasible and so we use a monte carlo estimate of V(x) denoted as V'(x) = 1/n*[g(z_1) + … + g(z_n)]. It is known that V'(x) is an unbiased estimate of V(x).
The question then is that if in the acceptance ratio of M-H mcmc algorithm, we use r(x) = exp(a*V'(x)) instead of exp(a*V(x)), whether the equilibrium distribution remains unchanged?
In general, if we are dealing with target distributions which are functions of expectations that are intractable to compute, but whose unbiased monte carlo estimates are (cheaply) available, then under what conditions the approximate acceptance ratio obtained by substituting monte carlo estimate in place of exact expectation will result in target distribution of the markov chain staying unchanged? Is there any work in approximate MCMC literature that deals with this issue? Any help is greatly appreciated.
Thanks,
Kshitij Judah
I don’t know the answer to this question off the top of my head, but I can point you to a nice talk by Geoff Nicholls related to this topic, which he gave at the Durham LMS/EPSRC Symposium this summer:
http://www.maths.dur.ac.uk/events/Meetings/LMS/2011/MDA11/movies/nicholls.wmv
I hope that is relevant and of interest.
Hello,
I tried the link you mentioned but I found that there is no audio in the video lecture. I will try emailing Geoff and see whether he can share his talk slides with me.
Please let me know if you come across any other material on this topic. Thanks!!
There is audio when I view it, though it is a bit quiet…
Yes,
I too can hear and view it now on my laptop using VLC player. Thanks!!
When p(x) takes the form of a product over many independent records: p(x1)p(x2)…p(xn) it is possible to form an unbiased estimator of the density using the Poisson estimator. Unfortunately, this estimator can be negative. An easy fix is to offset the estimator using a lower bound of log(p(x_i)), unfortunately, this potentially greatly increases variance.
I’ve looked at the generalized Poisson estimator, but it seems specific to diffusion processes and I’m not sure the technique generalizes to an arbitrary setting. Do you have thoughts on the issue or pointers?
You might be interested in this paper:
http://arxiv.org/abs/1306.4032
Nice article. Could you help me understand your third expression for the acceptance ratio $A$? I am not accustomed to seeing the VALUES of random variables in this quantity, just the DENSITIES evaluated at the old and new samples.
Nevermind, I got it. 🙂