Introduction
Particle MCMC (the use of approximate SMC proposals within exact MCMC algorithms) is arguably one of the most important developments in computational Bayesian inference of the 21st Century. The key concepts underlying these methods are described in a famously impenetrable “read paper” by Andrieu et al (2010). Probably the most generally useful method outlined in that paper is the particle marginal Metropolis-Hastings (PMMH) algorithm that I have described previously – that post is required preparatory reading for this one.
In this post I want to discuss some of the other topics covered in the pMCMC paper, leading up to a description of the particle Gibbs sampler. The basic particle Gibbs algorithm is arguably less powerful than PMMH for a few reasons, some of which I will elaborate on. But there is still a lot of active research concerning particle Gibbs-type algorithms, which are attempting to address some of the deficiencies of the basic approach. Clearly, in order to understand and appreciate the recent developments it is first necessary to understand the basic principles, and so that is what I will concentrate on here. I’ll then finish with some pointers to more recent work in this area.
PIMH
I will adopt the same approach and notation as for my post on the PMMH algorithm, using a simple bootstrap particle filter for a state space model as the SMC proposal. It is simplest to understand particle Gibbs first in the context of known static parameters, and so it is helpful to first reconsider the special case of the PMMH algorithm where there are no unknown parameters and only the state path, 
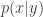

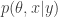
Here we envisage proposing a new path 
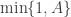


where 

and that in this case the marginal distribution of the accepted path is exactly 
Conditional SMC update
So far we have just recapped the previous post in the case of known parameters, but it gives us insight in how to proceed. A general issue with Metropolis independence samplers in high dimensions is that they often exhibit “sticky” behaviour, whereby an unusually “good” accepted path is hard to displace. This motivates consideration of a block-Gibbs-style algorithm where updates are used that are always accepted. It is clear that simply running a bootstrap filter will target the particle filter distribution

and so the marginal distribution of the accepted path will be the approximate 

as this will lead to accepted paths with the exact marginal distribution. For the PIMH this modification is achieved using a Metropolis-Hastings correction, but we now try to avoid this by instead conditioning on the previously accepted path. For this target the accepted paths have exactly the required marginal distribution, so we now write the target as the product of the marginal for the current path times a conditional for all of the remaining variables.

where in addition to the correct marginal for
![\displaystyle \frac{\tilde{q}(\mathbf{x}_0,\ldots,\mathbf{x}_T,\mathbf{a}_0,\ldots,\mathbf{a}_{T-1})} {\displaystyle p(x_0^{b_0^k})\left[\prod_{t=0}^{T-1} \pi_t^{b_t^k}p\left(x_{t+1}^{b_{t+1}^k}|x_t^{b_t^k}\right)\right]}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cfrac%7B%5Ctilde%7Bq%7D%28%5Cmathbf%7Bx%7D_0%2C%5Cldots%2C%5Cmathbf%7Bx%7D_T%2C%5Cmathbf%7Ba%7D_0%2C%5Cldots%2C%5Cmathbf%7Ba%7D_%7BT-1%7D%29%7D+%7B%5Cdisplaystyle+p%28x_0%5E%7Bb_0%5Ek%7D%29%5Cleft%5B%5Cprod_%7Bt%3D0%7D%5E%7BT-1%7D+%5Cpi_t%5E%7Bb_t%5Ek%7Dp%5Cleft%28x_%7Bt%2B1%7D%5E%7Bb_%7Bt%2B1%7D%5Ek%7D%7Cx_t%5E%7Bb_t%5Ek%7D%5Cright%29%5Cright%5D%7D&bg=ffffff&fg=333333&s=0&c=20201002)
The terms in the denominator are precisely the terms in the numerator corresponding to the current path, and hence “cancel out” the current path terms in the numerator. It is therefore clear that we can sample directly from this conditional distribution by running a bootstrap particle filter that includes the current path and which leaves the current path fixed. This is the conditional SMC (CSMC) update, which here is just a conditional bootstrap particle filter update. It is clear from the form of the conditional density how this filter must be constructed, but for completeness it is described below.
The bootstrap filter is run conditional on one trajectory. This is usually the trajectory sampled at the last run of the particle filter. The idea is that you do not sample new state or ancestor values for that one trajectory. Note that this guarantees that the conditioned on trajectory survives the filter right through to the final sweep of the filter at which point a new trajectory is picked from the current selection of 
Let 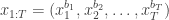

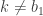
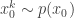


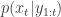
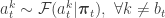


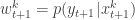
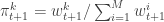


This defines a block Gibbs sampler which updates 


Before going on to consider the introduction of unknown parameters, it is worth considering the limitations of this method. One of the main motivations for considering a Gibbs-style update was concern about the “stickiness” of a Metropolis independence sampler. However, it is clear that conditional SMC updates also have the potential to stick. For a large number of time points, particle filter genealogies coalesce, or degenerate, to a single path. Since here we are conditioning on the current path, if there is coalescence, it is guaranteed to be to the previous path. So although the conditional SMC updates are always accepted, it is likely that much of the new path will be identical to the previous path, which is just another kind of “sticking” of the sampler. This problem with conditional SMC and particle Gibbs more generally is well recognised, and quite a bit of recent research activity in this area is directed at alleviating this sticking problem. The most obvious strategy to use is “backward sampling” (Godsill et al, 2004), which has been used in this context by Lindsten and Schon (2012), Whiteley et al (2010), and Chopin and Singh (2013), among others. Another related idea is “ancestor sampling” (Lindsten et al, 2014), which can be done in a single forward pass. Both of these techniques work well, but both rely on the tractability of the transition kernel of the state space model, which can be problematic in certain applications.
Particle Gibbs sampling
As we are working in the context of Gibbs-style updates, the introduction of static parameters, 
Note that the Gibbs update of
In a subsequent post I’ll show how to code up the particle Gibbs and other pMCMC algorithms in a reasonably efficient way.
References
- Andrieu, Christophe, Arnaud Doucet, and Roman Holenstein. “Particle Markov chain Monte Carlo methods.” Journal of the Royal Statistical Society: Series B (Statistical Methodology) 72.3 (2010): 269-342.
- Chopin, Nicolas, and Sumeetpal S. Singh. “On the particle Gibbs sampler.” arXiv preprint arXiv:1304.1887 (2013).
- Godsill, Simon J., Arnaud Doucet, and Mike West. “Monte Carlo smoothing for nonlinear time series.” Journal of the American Statistical Association 99.465 (2004).
- Lindsten, Fredrik, and Thomas B. Schön. “On the use of backward simulation in the particle Gibbs sampler.” Acoustics, Speech and Signal Processing (ICASSP), 2012 IEEE International Conference on. IEEE, 2012.
- Lindsten, Fredrik, Michael I. Jordan, and Thomas B. Schön. “Particle Gibbs with Ancestor Sampling.” arXiv preprint arXiv:1401.0604 (2014).
- Liu, Jun S. “The collapsed Gibbs sampler in Bayesian computations with applications to a gene regulation problem.” Journal of the American Statistical Association 89.427 (1994): 958-966.
- Whiteley, Nick, Christophe Andrieu, and Arnaud Doucet. “Efficient Bayesian inference for switching state-space models using discrete particle Markov chain Monte Carlo methods.” arXiv preprint arXiv:1011.2437 (2010).

Hi Darren,
This post (along with its preparatory posts) is very helpful to learn PG. Really appreciate your work.
Near to the end of this post, can you please give a concrete example of “a state space model with intractable transition kernel”?
Kai