Introduction
In previous posts I have discussed general issues regarding parallel MCMC and examined in detail parallel Monte Carlo on a multicore laptop. In those posts I used the C programming language in conjunction with the MPI parallel library in order to illustrate the concepts. In this post I want to take the example from the second post and re-examine it using the Scala programming language.
The toy problem considered in the parallel Monte Carlo post used 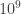
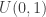

A very simple serial program to implement this algorithm is given below:
import java.util.concurrent.ThreadLocalRandom
import scala.math.exp
import scala.annotation.tailrec
object MonteCarlo {
@tailrec
def sum(its: Long,acc: Double): Double = {
if (its==0)
(acc)
else {
val u=ThreadLocalRandom.current().nextDouble()
sum(its-1,acc+exp(-u*u))
}
}
def main(args: Array[String]) = {
println("Hello")
val iters=1000000000
val result=sum(iters,0.0)
println(result/iters)
println("Goodbye")
}
}
Note that ThreadLocalRandom is a parallel random number generator introduced into recent versions of the Java programming language, which can be easily utilised from Scala code. Assuming that Scala is installed, this can be compiled and run with commands like
scalac monte-carlo.scala time scala MonteCarlo
This program works, and the timings (in seconds) for three runs are 57.79, 57.77 and 57.55 on the same laptop considered in the previous post. The first thing to note is that this Scala code is actually slightly faster than the corresponding C+MPI code in the single processor special case! Now that we have a good working implementation we should think how to parallelise it…
Parallel implementation
Before constructing a parallel implementation, we will first construct a slightly re-factored serial version that will be easier to parallelise. The simplest way to introduce parallelisation into Scala code is to parallelise a map over a collection. We therefore need a collection and a map to apply to it. Here we will just divide our 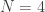
import java.util.concurrent.ThreadLocalRandom
import scala.math.exp
import scala.annotation.tailrec
object MonteCarlo {
@tailrec
def sum(its: Long,acc: Double): Double = {
if (its==0)
(acc)
else {
val u=ThreadLocalRandom.current().nextDouble()
sum(its-1,acc+exp(-u*u))
}
}
def main(args: Array[String]) = {
println("Hello")
val N=4
val iters=1000000000
val its=iters/N
val sums=(1 to N).toList map {x => sum(its,0.0)}
val result=sums.reduce(_+_)
println(result/iters)
println("Goodbye")
}
}
Running this new code confirms that it works and gives similar estimates for the Monte Carlo integral as the previous version. The timings for 3 runs on my laptop were 57.57, 57.67 and 57.80, similar to the previous version of the code. So far so good. But how do we make it parallel? Like this:
import java.util.concurrent.ThreadLocalRandom
import scala.math.exp
import scala.annotation.tailrec
object MonteCarlo {
@tailrec
def sum(its: Long,acc: Double): Double = {
if (its==0)
(acc)
else {
val u=ThreadLocalRandom.current().nextDouble()
sum(its-1,acc+exp(-u*u))
}
}
def main(args: Array[String]) = {
println("Hello")
val N=4
val iters=1000000000
val its=iters/N
val sums=(1 to N).toList.par map {x => sum(its,0.0)}
val result=sums.reduce(_+_)
println(result/iters)
println("Goodbye")
}
}
That’s it! It’s now parallel. Studying the above code reveals that the only difference from the previous version is the introduction of the 4 characters .par in line 22 of the code. R programmers will find this very much analagous to using lapply() versus mclapply() in R code. The function par converts the collection (here an immutable List) to a parallel collection (here an immutable parallel List), and then subsequent maps, filters, etc., can be computed in parallel on appropriate multicore architectures. Timings for 3 runs on my laptop were 20.74, 20.82 and 20.88. Note that these timings are faster than the timings for N=4 processors for the corresponding C+MPI code…
Varying the size of the parallel collection
We can trivially modify the previous code to make the size of the parallel collection, N, a command line argument:
import java.util.concurrent.ThreadLocalRandom
import scala.math.exp
import scala.annotation.tailrec
object MonteCarlo {
@tailrec
def sum(its: Long,acc: Double): Double = {
if (its==0)
(acc)
else {
val u=ThreadLocalRandom.current().nextDouble()
sum(its-1,acc+exp(-u*u))
}
}
def main(args: Array[String]) = {
println("Hello")
val N=args(0).toInt
val iters=1000000000
val its=iters/N
val sums=(1 to N).toList.par map {x => sum(its,0.0)}
val result=sums.reduce(_+_)
println(result/iters)
println("Goodbye")
}
}
We can now run this code with varying sizes of N in order to see how the runtime of the code changes as the size of the parallel collection increases. Timings on my laptop are summarised in the table below.
N T1 T2 T3 1 57.67 57.62 57.83 2 32.20 33.24 32.76 3 26.63 26.60 26.63 4 20.99 20.92 20.75 5 20.13 18.70 18.76 6 16.57 16.52 16.59 7 15.72 14.92 15.27 8 13.56 13.51 13.32 9 18.30 18.13 18.12 10 17.25 17.33 17.22 11 17.04 16.99 17.09 12 15.95 15.85 15.91 16 16.62 16.68 16.74 32 15.41 15.54 15.42 64 15.03 15.03 15.28
So we see that the timings decrease steadily until the size of the parallel collection hits 8 (the number of processors my hyper-threaded quad-core presents via Linux), and then increases very slightly, but not much as the size of the collection increases. This is better than the case of C+MPI where performance degrades noticeably if too many processes are requested. Here, the Scala compiler and JVM runtime manage an appropriate number of threads for the collection irrespective of the actual size of the collection. Also note that all of the timings are faster than the corresponding C+MPI code discussed in the previous post.
However, the notion that the size of the collection is irrelevant is only true up to a point. Probably the most natural way to code this algorithm would be as:
import java.util.concurrent.ThreadLocalRandom
import scala.math.exp
object MonteCarlo {
def main(args: Array[String]) = {
println("Hello")
val iters=1000000000
val sums=(1 to iters).toList map {x => ThreadLocalRandom.current().nextDouble()} map {x => exp(-x*x)}
val result=sums.reduce(_+_)
println(result/iters)
println("Goodbye")
}
}
or as the parallel equivalent
import java.util.concurrent.ThreadLocalRandom
import scala.math.exp
object MonteCarlo {
def main(args: Array[String]) = {
println("Hello")
val iters=1000000000
val sums=(1 to iters).toList.par map {x => ThreadLocalRandom.current().nextDouble()} map {x => exp(-x*x)}
val result=sums.reduce(_+_)
println(result/iters)
println("Goodbye")
}
}
Although these algorithms are in many ways cleaner and more natural, they will bomb out with a lack of heap space unless you have a huge amount of RAM, as they rely on having all

A very interesting read. I’m wondering how scala would fare against C+OpenMP. I think the reason why C+MPI is slower in this application is that there is communication overhead when performing the MPI_Reduce and I also seem to recall that spawning threads in MPI is a lot slower than spawning threads in OpenMP. I think there is an initial start up overhead with MPI_Init – two reasons why I prefer to use OpenMP on shared memory multicore machines. I hope that somebody can confirm this suspicion for me. What are the scientific libraries like for scala?
I agree that it would be interesting to look at OpenMP, though I suspect that it won’t make much difference here, as there are few threads and little inter-process communication. I guess that here the difference will be something trivial like Java’s ThreadLocalRandom being a bit faster than the SPRNG parallel generator, or some such. But the point of the post is not to argue that Scala is really faster than C+MPI (which I think is unlikely to be true in general), but instead that it is roughly the same speed. So you shouldn’t just choose C (or C++) because you think it is much faster than everything else. If you are choosing C/C++ it should be because you think that it is an elegant language for expressing the solution to your problem! 😉
Regarding scientific libraries in Scala, things are steadily improving – see my recent post on Scala and Breeze, for example.
Never convert a range to a list and then call `par` on it. Lists require conversion to be parallelizable, as explained here: http://docs.scala-lang.org/overviews/parallel-collections/conversions.html
Instead, call `toArray` or `toVector` directly.
Also, you should use the `aggregate` parallel operation in this example to avoid calling `map` at all and occupying huge amounts of RAM. This is __much__ efficient:
(1 to iters).aggregate(0.0)((acc, x) => {
val num = ThreadLocalRandom.current.nextDouble()
acc + exp(num * num)
}, _ + _)
In fact, for number crunching, use ScalaBlitz – it uses macros to optimize operations, and is a lot quicker for these type of computations. An optimizer for the `map`,`map`,`reduce` kind of programs you described is under development.
If you want to turn your Monte Carlo example into an example application, and submit a PR to ScalaBlitz:
http://scala-blitz.github.io/
we’ll add it to the distribution.
Hi there. Interesting post. Would I be right in thinking that the sequence for the pseudo random number generator would not be guaranteed, since it is being run in parallel?
In your case, this is not an issue since each run is independent of each other; but say you were evaluating another integral at the same time? It would re-use the threads, and thus use the same ThreadLocalRandom and so, the results would not be guaranteed repeatable?
Yes, that’s correct. Breeze defaults to using ThreadLocalRandom, which I think is a very good default. However, you can specify other random number generators if you prefer. This is very simple to do in the case of single threaded code, but will require great care for multi-threaded codes like this.