Part 2: The log posterior
Introduction
This is the second part in a series of posts on MCMC-based Bayesian inference for a logistic regression model. If you are new to this series, please go back to Part 1.
In the previous post we looked at the basic modelling concepts, and how to fit the model using a variety of PPLs. In this post we will prepare for doing MCMC by considering the problem of computing the unnormalised log posterior for the model. We will then see how this posterior can be implemented in several different languages and libraries.
Derivation
Basic structure
In Bayesian inference the posterior distribution is just the conditional distribution of the model parameters given the data, and therefore proportional to the joint distribution of the model and data. We often write this as
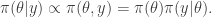
Taking logs we have
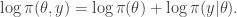
So (up to an additive constant) the log posterior is just the sum of the log prior and log likelihood. There are many good (numerical) reasons why we try to work exclusively with the log posterior and try to avoid ever evaluating the raw posterior density.
For our example logistic regression model, the parameter vector 

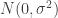

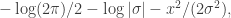
and the initial constant term normalising the density can often be dropped.
Log-likelihood (first attempt)
Information from the data comes into the log posterior via the log-likelihood. The typical way to derive the likelihood for problems of this type is to assume the usual binary encoding of the data (success 1, failure 0). Then, for a Bernoulli observation with probability 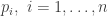

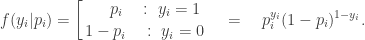
Taking logs and then switching to parameter 
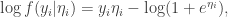
and summing over 

In the context of logistic regression, 

![\displaystyle \ell(\beta;y) = y^\textsf{T}X\beta - \mathbf{1}^\textsf{T}\log(\mathbf{1}+\exp[X\beta]).](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cell%28%5Cbeta%3By%29+%3D+y%5E%5Ctextsf%7BT%7DX%5Cbeta+-+%5Cmathbf%7B1%7D%5E%5Ctextsf%7BT%7D%5Clog%28%5Cmathbf%7B1%7D%2B%5Cexp%5BX%5Cbeta%5D%29.+&bg=ffffff&fg=333333&s=0&c=20201002)
This is a perfectly good way of expressing the log-likelihood, and we will come back to it later when we want the gradient of the log-likelihood, but it turns out that there is a similar-but-different way of deriving it that results in an expression that is equivalent but slightly cheaper to evaluate.
Log-likelihood (second attempt)
For our second attempt, we will assume that the data is coded in a different way. Instead of the usual binary encoding, we will assume that the observation 

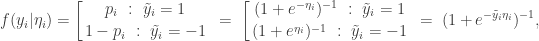
and hence

Summing over observations gives
![\displaystyle \ell(\eta;\tilde y) = -\mathbf{1}\cdot \log(\mathbf{1}+\exp[-\tilde y\circ \eta]),](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cell%28%5Ceta%3B%5Ctilde+y%29+%3D+-%5Cmathbf%7B1%7D%5Ccdot+%5Clog%28%5Cmathbf%7B1%7D%2B%5Cexp%5B-%5Ctilde+y%5Ccirc+%5Ceta%5D%29%2C+&bg=ffffff&fg=333333&s=0&c=20201002)
where 
![\displaystyle \ell(\beta;\tilde y) = -\mathbf{1}^\textsf{T} \log(\mathbf{1}+\exp[-\tilde y\circ X\beta]).](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cell%28%5Cbeta%3B%5Ctilde+y%29+%3D+-%5Cmathbf%7B1%7D%5E%5Ctextsf%7BT%7D+%5Clog%28%5Cmathbf%7B1%7D%2B%5Cexp%5B-%5Ctilde+y%5Ccirc+X%5Cbeta%5D%29.+&bg=ffffff&fg=333333&s=0&c=20201002)
This likelihood is a bit cheaper to evaluate that the one previously derived. If we prefer to write in terms of the original data encoding, we can obviously do so as
![\displaystyle \ell(\beta; y) = -\mathbf{1}^\textsf{T} \log(\mathbf{1}+\exp[-(2y-\mathbf{1})\circ (X\beta)]),](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cell%28%5Cbeta%3B+y%29+%3D+-%5Cmathbf%7B1%7D%5E%5Ctextsf%7BT%7D+%5Clog%28%5Cmathbf%7B1%7D%2B%5Cexp%5B-%282y-%5Cmathbf%7B1%7D%29%5Ccirc+%28X%5Cbeta%29%5D%29%2C+&bg=ffffff&fg=333333&s=0&c=20201002)
and in practice, it is this version that is typically used. To be clear, as an algebraic function of 
Implementation
R
In R we can create functions for evaluating the log-likelihood, log-prior and log-posterior as follows (assuming that X and y are in scope).
ll = function(beta)
sum(-log(1 + exp(-(2*y - 1)*(X %*% beta))))
lprior = function(beta)
dnorm(beta[1], 0, 10, log=TRUE) + sum(dnorm(beta[-1], 0, 1, log=TRUE))
lpost = function(beta) ll(beta) + lprior(beta)
Python
In Python (with NumPy and SciPy) we can define equivalent functions with
def ll(beta):
return np.sum(-np.log(1 + np.exp(-(2*y - 1)*(X.dot(beta)))))
def lprior(beta):
return (sp.stats.norm.logpdf(beta[0], loc=0, scale=10) +
np.sum(sp.stats.norm.logpdf(beta[range(1,p)], loc=0, scale=1)))
def lpost(beta):
return ll(beta) + lprior(beta)
JAX
Python, like R, is a dynamic language, and relatively slow for MCMC algorithms. JAX is a tensor computation framework for Python that embeds a pure functional differentiable array processing language inside Python. JAX can JIT-compile high-performance code for both CPU and GPU, and has good support for parallelism. It is rapidly becoming the preferred way to develop high-performance sampling algorithms within the Python ecosystem. We can encode our log-posterior in JAX as follows.
@jit
def ll(beta):
return jnp.sum(-jnp.log(1 + jnp.exp(-(2*y - 1)*jnp.dot(X, beta))))
@jit
def lprior(beta):
return (jsp.stats.norm.logpdf(beta[0], loc=0, scale=10) +
jnp.sum(jsp.stats.norm.logpdf(beta[jnp.array(range(1,p))], loc=0, scale=1)))
@jit
def lpost(beta):
return ll(beta) + lprior(beta)
Scala
JAX is a pure functional programming language embedded in Python. Pure functional programming languages are intrinsically more scalable and compositional than imperative languages such as R and Python, and are much better suited to exploit concurrency and parallelism. I’ve given a bunch of talks about this recently, so if you are interested in this, perhaps start with the materials for my Laplace’s Demon talk. Scala and Haskell are arguably the current best popular general purpose functional programming languages, so it is possibly interesting to consider the use of these languages for the development of scalable statistical inference codes. Since both languages are statically typed compiled functional languages with powerful type systems, they can be highly performant. However, neither is optimised for numerical (tensor) computation, so you should not expect that they will have performance comparable with optimised tensor computation frameworks such as JAX. We can encode our log-posterior in Scala (with Breeze) as follows:
def ll(beta: DVD): Double =
sum(-log(ones + exp(-1.0*(2.0*y - ones)*:*(X * beta))))
def lprior(beta: DVD): Double =
Gaussian(0,10).logPdf(beta(0)) +
sum(beta(1 until p).map(Gaussian(0,1).logPdf(_)))
def lpost(beta: DVD): Double = ll(beta) + lprior(beta)
Spark
Apache Spark is a Scala library for distributed "big data" processing on clusters of machines. Despite fundamental differences, there is a sense in which Spark for Scala is a bit analogous to JAX for Python: both Spark and JAX are concerned with scalability, but they are targeting rather different aspects of scalability: JAX is concerned with getting regular sized data processing algorithms to run very fast (on GPUs), whereas Spark is concerned with running huge data processing tasks quickly by distributing work over clusters of machines. Despite obvious differences, the fundamental pure functional computational model adopted by both systems is interestingly similar: both systems are based on lazy transformations of immutable data structures using pure functions. This is a fundamental pattern for scalable data processing transcending any particular language, library or framework. We can encode our log posterior in Spark as follows.
def ll(beta: DVD): Double =
df.map{row =>
val y = row.getAs[Double](0)
val x = BDV.vertcat(BDV(1.0),toBDV(row.getAs[DenseVector](1)))
-math.log(1.0 + math.exp(-1.0*(2.0*y-1.0)*(x.dot(beta))))}.reduce(_+_)
def lprior(beta: DVD): Double =
Gaussian(0,10).logPdf(beta(0)) +
sum(beta(1 until p).map(Gaussian(0,1).logPdf(_)))
def lpost(beta: DVD): Double =
ll(beta) + lprior(beta)
Haskell
Haskell is an old, lazy pure functional programming language with an advanced type system, and remains the preferred language for the majority of functional programming language researchers. Hmatrix is the standard high performance numerical linear algebra library for Haskell, so we can use it to encode our log-posterior as follows.
ll :: Matrix Double -> Vector Double -> Vector Double -> Double
ll x y b = (negate) (vsum (cmap log (
(scalar 1) + (cmap exp (cmap (negate) (
(((scalar 2) * y) - (scalar 1)) * (x #> b)
)
)))))
pscale :: [Double] -- prior standard deviations
pscale = [10.0, 1, 1, 1, 1, 1, 1, 1]
lprior :: Vector Double -> Double
lprior b = sum $ (\x -> logDensity (normalDistr 0.0 (snd x)) (fst x)) <$> (zip (toList b) pscale)
lpost :: Matrix Double -> Vector Double -> Vector Double -> Double
lpost x y b = (ll x y b) + (lprior b)
Again, a reminder that, here and elsewhere, there are various optimisations could be done that I’m not bothering with. This is all just proof-of-concept code.
Dex
JAX proves that a pure functional DSL for tensor computation can be extremely powerful and useful. But embedding such a language in a dynamic imperative language like Python has a number of drawbacks. Dex is an experimental statically typed stand-alone DSL for differentiable array and tensor programming that attempts to combine some of the correctness and composability benefits of powerful statically typed functional languages like Scala and Haskell with the performance benefits of tensor computation systems like JAX. It is currently rather early its development, but seems very interesting, and is already quite useable. We can encode our log-posterior in Dex as follows.
def ll (b: (Fin 8)=>Float) : Float =
neg $ sum (log (map (\ x. (exp x) + 1) ((map (\ yi. 1 - 2*yi) y)*(x **. b))))
pscale = [10.0, 1, 1, 1, 1, 1, 1, 1] -- prior SDs
prscale = map (\ x. 1.0/x) pscale
def lprior (b: (Fin 8)=>Float) : Float =
bs = b*prscale
neg $ sum ((log pscale) + (0.5 .* (bs*bs)))
def lpost (b: (Fin 8)=>Float) : Float =
(ll b) + (lprior b)
Next steps
Now that we have a way of evaluating the log posterior, we can think about constructing Markov chains having the posterior as their equilibrium distribution. In the next post we will look at one of the simplest ways of doing this: the Metropolis algorithm.
Complete runnable scripts are available from this public github repo.
