Bayesian variable selection
In a previous post I gave a quick introduction to using the rjags R package to access the JAGS Bayesian inference from within R. In this post I want to give a quick guide to using rjags for Bayesian variable selection. I intend to use this post as a starting point for future posts on Bayesian model and variable selection using more sophisticated approaches.
I will use the simple example of multiple linear regression to illustrate the ideas, but it should be noted that I’m just using that as an example. It turns out that in the context of linear regression there are lots of algebraic and computational tricks which can be used to simplify the variable selection problem. The approach I give here is therefore rather inefficient for linear regression, but generalises to more complex (non-linear) problems where analytical and computational short-cuts can’t be used so easily.
Consider a linear regression problem with n observations and p covariates, which we can write in matrix form as
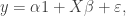
where 


The simplest and most natural way to tackle the variable selection problem from a Bayesian perspective is to introduce an indicator random variable 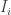
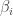




Simulating some data
In order to see how things work, let’s first simulate some data from a regression model with geometrically decaying regression coefficients.
n=500 p=20 X=matrix(rnorm(n*p),ncol=p) beta=2^(0:(1-p)) print(beta) alpha=3 tau=2 eps=rnorm(n,0,1/sqrt(tau)) y=alpha+as.vector(X%*%beta + eps)
Let’s also fit the model by least squares.
mod=lm(y~X) print(summary(mod))
This should give output something like the following.
Call:
lm(formula = y ~ X)
Residuals:
Min 1Q Median 3Q Max
-1.62390 -0.48917 -0.02355 0.45683 2.35448
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 3.0565406 0.0332104 92.036 < 2e-16 ***
X1 0.9676415 0.0322847 29.972 < 2e-16 ***
X2 0.4840052 0.0333444 14.515 < 2e-16 ***
X3 0.2680482 0.0320577 8.361 6.8e-16 ***
X4 0.1127954 0.0314472 3.587 0.000369 ***
X5 0.0781860 0.0334818 2.335 0.019946 *
X6 0.0136591 0.0335817 0.407 0.684379
X7 0.0035329 0.0321935 0.110 0.912662
X8 0.0445844 0.0329189 1.354 0.176257
X9 0.0269504 0.0318558 0.846 0.397968
X10 0.0114942 0.0326022 0.353 0.724575
X11 -0.0045308 0.0330039 -0.137 0.890868
X12 0.0111247 0.0342482 0.325 0.745455
X13 -0.0584796 0.0317723 -1.841 0.066301 .
X14 -0.0005005 0.0343499 -0.015 0.988381
X15 -0.0410424 0.0334723 -1.226 0.220742
X16 0.0084832 0.0329650 0.257 0.797026
X17 0.0346331 0.0327433 1.058 0.290718
X18 0.0013258 0.0328920 0.040 0.967865
X19 -0.0086980 0.0354804 -0.245 0.806446
X20 0.0093156 0.0342376 0.272 0.785671
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 0.7251 on 479 degrees of freedom
Multiple R-squared: 0.7187, Adjusted R-squared: 0.707
F-statistic: 61.2 on 20 and 479 DF, p-value: < 2.2e-16
The first 4 variables are “highly significant” and the 5th is borderline.
Saturated model
We can fit the saturated model using JAGS with the following code.
require(rjags)
data=list(y=y,X=X,n=n,p=p)
init=list(tau=1,alpha=0,beta=rep(0,p))
modelstring="
model {
for (i in 1:n) {
mean[i]<-alpha+inprod(X[i,],beta)
y[i]~dnorm(mean[i],tau)
}
for (j in 1:p) {
beta[j]~dnorm(0,0.001)
}
alpha~dnorm(0,0.0001)
tau~dgamma(1,0.001)
}
"
model=jags.model(textConnection(modelstring),
data=data,inits=init)
update(model,n.iter=100)
output=coda.samples(model=model,variable.names=c("alpha","beta","tau"),
n.iter=10000,thin=1)
print(summary(output))
plot(output)
I’ve hard-coded various hyper-parameters in the script which are vaguely reasonable for this kind of problem. I won’t include all of the output in this post, but this works fine and gives sensible results. However, it does not address the variable selection problem.
Basic variable selection
Let’s now modify the above script to do basic variable selection in the style of Kuo and Mallick.
data=list(y=y,X=X,n=n,p=p)
init=list(tau=1,alpha=0,betaT=rep(0,p),ind=rep(0,p))
modelstring="
model {
for (i in 1:n) {
mean[i]<-alpha+inprod(X[i,],beta)
y[i]~dnorm(mean[i],tau)
}
for (j in 1:p) {
ind[j]~dbern(0.2)
betaT[j]~dnorm(0,0.001)
beta[j]<-ind[j]*betaT[j]
}
alpha~dnorm(0,0.0001)
tau~dgamma(1,0.001)
}
"
model=jags.model(textConnection(modelstring),
data=data,inits=init)
update(model,n.iter=1000)
output=coda.samples(model=model,
variable.names=c("alpha","beta","ind","tau"),
n.iter=10000,thin=1)
print(summary(output))
plot(output)
Note that I’ve hard-coded an expectation that around 20% of variables should be included in the model. Again, I won’t include all of the output here, but the posterior mean of the indicator variables can be interpreted as posterior probabilities that the variables should be included in the model. Inspecting the output then reveals that the first three variables have a posterior probability of very close to one, the 4th variable has a small but non-negligible probability of inclusion, and the other variables all have very small probabilities of inclusion.
This is fine so far as it goes, but is not entirely satisfactory. One problem is that the choice of a “fixed effects” prior for the regression coefficients of the included variables is likely to lead to a Lindley’s paradox type situation, and a consequent under-selection of variables. It is arguably better to model the distribution of included variables using a “random effects” approach, leading to a more appropriate distribution for the included variables.
Variable selection with random effects
Adopting a random effects distribution for the included coefficients that is normal with mean zero and unknown variance helps to combat Lindley’s paradox, and can be implemented as follows.
data=list(y=y,X=X,n=n,p=p)
init=list(tau=1,taub=1,alpha=0,betaT=rep(0,p),ind=rep(0,p))
modelstring="
model {
for (i in 1:n) {
mean[i]<-alpha+inprod(X[i,],beta)
y[i]~dnorm(mean[i],tau)
}
for (j in 1:p) {
ind[j]~dbern(0.2)
betaT[j]~dnorm(0,taub)
beta[j]<-ind[j]*betaT[j]
}
alpha~dnorm(0,0.0001)
tau~dgamma(1,0.001)
taub~dgamma(1,0.001)
}
"
model=jags.model(textConnection(modelstring),
data=data,inits=init)
update(model,n.iter=1000)
output=coda.samples(model=model,
variable.names=c("alpha","beta","ind","tau","taub"),
n.iter=10000,thin=1)
print(summary(output))
plot(output)
This leads to a large inclusion probability for the 4th variable, and non-negligible inclusion probabilities for the next few (it is obviously somewhat dependent on the simulated data set). This random effects variable selection modelling approach generally performs better, but it still has the potentially undesirable feature of hard-coding the probability of variable inclusion. Under the prior model, the number of variables included is binomial, and the binomial distribution is rather concentrated about its mean. Where there is a general desire to control the degree of sparsity in the model, this is a good thing, but if there is considerable uncertainty about the degree of sparsity that is anticipated, then a more flexible model may be desirable.
Variable selection with random effects and a prior on the inclusion probability
The previous model can be modified by introducing a Beta prior for the model inclusion probability. This induces a distribution for the number of included variables which has longer tails than the binomial distribution, allowing the model to learn about the degree of sparsity.
data=list(y=y,X=X,n=n,p=p)
init=list(tau=1,taub=1,pind=0.5,alpha=0,betaT=rep(0,p),ind=rep(0,p))
modelstring="
model {
for (i in 1:n) {
mean[i]<-alpha+inprod(X[i,],beta)
y[i]~dnorm(mean[i],tau)
}
for (j in 1:p) {
ind[j]~dbern(pind)
betaT[j]~dnorm(0,taub)
beta[j]<-ind[j]*betaT[j]
}
alpha~dnorm(0,0.0001)
tau~dgamma(1,0.001)
taub~dgamma(1,0.001)
pind~dbeta(2,8)
}
"
model=jags.model(textConnection(modelstring),
data=data,inits=init)
update(model,n.iter=1000)
output=coda.samples(model=model,
variable.names=c("alpha","beta","ind","tau","taub","pind"),
n.iter=10000,thin=1)
print(summary(output))
plot(output)
It turns out that for this particular problem the posterior distribution is not very different to the previous case, as for this problem the hard-coded choice of 20% is quite consistent with the data. However, the variable inclusion probabilities can be rather sensitive to the choice of hard-coded proportion.
Conclusion
Bayesian variable selection (and model selection more generally) is a very delicate topic, and there is much more to say about it. In this post I’ve concentrated on the practicalities of introducing variable selection into JAGS models. For further reading, I highly recommend the review of O’Hara and Sillanpaa (2009), which discusses other computational algorithms for variable selection. I intend to discuss some of the other methods in future posts.
References
- O’Hara, R. and Sillanpaa, M. (2009) A review of Bayesian variable selection methods: what, how and which. Bayesian Analysis, 4(1):85-118. [DOI, PDF, Supp, BUGS Code]
- Kuo, L. and Mallick, B. (1998) Variable selection for regression models. Sankhya B, 60(1):65-81.

The approach of introducing 0-1 indicators in Bayesian model selection goes back well before 1998. I think it’s a bit much to say that Kuo and Mallick introduced such an idea.
Just by way of example (one from 1996 – but Smith and Kohn don’t originate the idea either):
http://www.sciencedirect.com/science/article/pii/0304407695017631
OK – fair comment – I’ve changed “introduced” to “used”. The point is that it is important to distinguish between the many closely related but subtly different models for BVS, and for that I’m following the terminology of O’Hara and Sillanpaa.
The first time that the zero-one indicators are used are in SSVS (George and McCullogh, 1993, Jasa) which is slightly different that KM. Also see the work of Dellaportas Forster and Ntzoufras (2002) in Stats+Comp that compares the methods and introduces a more efficient gibbs sampler for variable selection. Also the same group has published a paper in 2000 with BUGS code and I have a paper in 2003 in JSS explaining in detail how you can implement these methods in BUGS. Chapter 11 in my book also illustrates how you can implement the variable selection Gibbs samplers in WinBUGS. Finally, In a recent tutorial for WinBUGS in WIRES Computational Statistics we explain how Lasso methods and Lasso based variable selection can be implemented in WinBUGS.
Regards
Ioannis
Such a small world! Sillanpaa was my professor of the course of Bayesian Variable Selection in Finland 🙂
Hope you enjoy a summary of that course in the form of three posts I wrote a while ago
http://worldofpiggy.com/2012/10/04/bayesian-variable-selection-in-genetics-part-13/
http://worldofpiggy.com/2012/10/08/bayesian-variable-selection-in-genetics-part-23/
http://worldofpiggy.com/2012/10/16/bayesian-variable-selection-in-genetics-part-33/
Great post (even if I got here more >1 year later)!
It did make me wonder whether a Bayes Factor can be constructed from the indicator variables for model selection?
If instead of choosing pind=0.2 but rather 0.5 so that model priors were equal, would the ratio of ind[j]==1 to ind[j]==0 be the Bayes Factor for a model including variable j?
Thanks for the great blogging!
Great post even another one more year later. And I have the same question. How to calculate Bayes Factor here? Thank Darren’s great blogging and Sameer’s question. If you have figure out the answer, please share it with me.
The question isn’t very well posed. A Bayes factor compares 2 models, but here we have 2^p models, and it isn’t very clear why we’d be interested in specifically comparing any two of them.
Is there a good review paper for the history and progress of variable selection?
I just saw the O’Hara reference :v but if anyone knows of any others too…
Hello, thank you for your great post related to the Bayesian variable selection for linear models. I have a question, in the last section, you used Beta(2,8) prior for the inclusion probability p, it seems that often no-informative prior uniform(0,1) is imposed for p, here I understand that you want to learn about degree of sparsity so instead you use Beta prior, do you know any reference paper that mentioned Beta prior is reasonable to be used even if you don’t know any prior information for p?
The beta distribution is conjugate in this context. Note that the Uniform(0,1) is a special case of the beta, so you are using a beta if you use the Uniform(0,1).
Thank you for your reply. I have one more question, why do you use Beta(2,8) rather than other Beta distribution, say, Beta(1,8), Beta(0.5,0.5), Unif(0,1)?
Right now I am doing some data analysis, I need to justify that I could choose the prior Beta(2,8) for inclusion probability p, since I found that the results are a little different if I use different beta distributions as prior for inclusion probability.
No deep reason. It has a smallish mean, and the right kind of shape – not too concentrated.
See Scott and Berger 2010 “BAYES AND EMPIRICAL-BAYES MULTIPLICITY ADJUSTMENT
IN THE VARIABLE-SELECTION PROBLEM” for comparisons between a uniform and beta prior. By integrating out the inclusion probability p it is interesting to consider the marginal prior distribution induced over the model space. See figure 1 for the log prior vs model size. Uniform prior favours relatively small and large models, for which the latter could be considered undesirable.
Thanks for a nice and clear tutorial. What happens if the model is binomial? Can this approach still be used? I would imagine that the prior on the inclusion probability differs for a binomial model?
Sure, the same approach should work for a binomial GLM.
Ok, thank for the answer. I am wondering, because in my model (binomial), the betas are totally different when the Indicator is included compared with the model without indicators (when using the last approach for indicators that you have presented here).