Part 5: the Metropolis-adjusted Langevin algorithm (MALA)
Introduction
This is the fifth part in a series of posts on MCMC-based Bayesian inference for a logistic regression model. If you are new to this series, please go back to Part 1.
In the previous post we saw how to use Langevin dynamics to construct an approximate MCMC scheme using the gradient of the log target distribution. Each step of the algorithm involved simulating from the Euler-Maruyama approximation to the transition kernel of the process, based on some pre-specified step size, 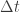
Fortunately, there is an easy way to make the algorithm "exact" (in the sense that the equilibrium distribution of the Markov chain will be the exact target distribution), for any finite step size,
Implementations
R
First we need a function to generate a M-H kernel.
mhKernel = function(logPost, rprop, dprop = function(new, old, ...) { 1 })
function(x, ll) {
prop = rprop(x)
llprop = logPost(prop)
a = llprop - ll + dprop(x, prop) - dprop(prop, x)
if (log(runif(1)) < a)
list(x=prop, ll=llprop)
else
list(x=x, ll=ll)
}
Then we can easily write a function for returning a MALA kernel that makes use of this M-H function.
malaKernel = function(lpi, glpi, dt = 1e-4, pre = 1) {
sdt = sqrt(dt)
spre = sqrt(pre)
advance = function(x) x + 0.5*pre*glpi(x)*dt
mhKernel(lpi, function(x) rnorm(p, advance(x), spre*sdt),
function(new, old) sum(dnorm(new, advance(old), spre*sdt, log=TRUE)))
}
Notice that our MALA function requires as input both the gradient of the log posterior (for the proposal) and the log posterior itself (for the M-H correction). Other details are as we have already seen – see the full runnable script.
Python
Again, we need a M-H kernel
def mhKernel(lpost, rprop, dprop = lambda new, old: 1.):
def kernel(x, ll):
prop = rprop(x)
lp = lpost(prop)
a = lp - ll + dprop(x, prop) - dprop(prop, x)
if (np.log(np.random.rand()) < a):
x = prop
ll = lp
return x, ll
return kernel
and then a MALA kernel
def malaKernel(lpi, glpi, dt = 1e-4, pre = 1):
p = len(init)
sdt = np.sqrt(dt)
spre = np.sqrt(pre)
advance = lambda x: x + 0.5*pre*glpi(x)*dt
return mhKernel(lpi, lambda x: advance(x) + np.random.randn(p)*spre*sdt,
lambda new, old: np.sum(sp.stats.norm.logpdf(new, loc=advance(old), scale=spre*sdt)))
See the full runnable script for further details.
JAX
If we want our algorithm to run fast, and if we want to exploit automatic differentiation to avoid the need to manually compute gradients, then we can easily convert the above code to use JAX.
def mhKernel(lpost, rprop, dprop = jit(lambda new, old: 1.)):
@jit
def kernel(key, x, ll):
key0, key1 = jax.random.split(key)
prop = rprop(key0, x)
lp = lpost(prop)
a = lp - ll + dprop(x, prop) - dprop(prop, x)
accept = (jnp.log(jax.random.uniform(key1)) < a)
return jnp.where(accept, prop, x), jnp.where(accept, lp, ll)
return kernel
def malaKernel(lpi, dt = 1e-4, pre = 1):
p = len(init)
glpi = jit(grad(lpost))
sdt = jnp.sqrt(dt)
spre = jnp.sqrt(pre)
advance = jit(lambda x: x + 0.5*pre*glpi(x)*dt)
return mhKernel(lpi, jit(lambda k, x: advance(x) +
jax.random.normal(k, [p])*spre*sdt),
jit(lambda new, old:
jnp.sum(jsp.stats.norm.logpdf(new,
loc=advance(old), scale=spre*sdt))))
See the full runnable script for further details.
Scala
def mhKernel[S](
logPost: S => Double, rprop: S => S,
dprop: (S, S) => Double = (n: S, o: S) => 1.0
): ((S, Double)) => (S, Double) =
val r = Uniform(0.0,1.0)
state =>
val (x0, ll0) = state
val x = rprop(x0)
val ll = logPost(x)
val a = ll - ll0 + dprop(x0, x) - dprop(x, x0)
if (math.log(r.draw()) < a)
(x, ll)
else
(x0, ll0)
def malaKernel(lpi: DVD => Double, glpi: DVD => DVD, pre: DVD, dt: Double = 1e-4) =
val sdt = math.sqrt(dt)
val spre = sqrt(pre)
val p = pre.length
def advance(beta: DVD): DVD =
beta + (0.5*dt)*(pre*:*glpi(beta))
def rprop(beta: DVD): DVD =
advance(beta) + sdt*spre.map(Gaussian(0,_).sample())
def dprop(n: DVD, o: DVD): Double =
val ao = advance(o)
(0 until p).map(i => Gaussian(ao(i), spre(i)*sdt).logPdf(n(i))).sum
mhKernel(lpi, rprop, dprop)
See the full runnable script for further details.
Haskell
mhKernel :: (StatefulGen g m) => (s -> Double) -> (s -> g -> m s) ->
(s -> s -> Double) -> g -> (s, Double) -> m (s, Double)
mhKernel logPost rprop dprop g (x0, ll0) = do
x <- rprop x0 g
let ll = logPost(x)
let a = ll - ll0 + (dprop x0 x) - (dprop x x0)
u <- (genContVar (uniformDistr 0.0 1.0)) g
let next = if ((log u) < a)
then (x, ll)
else (x0, ll0)
return next
malaKernel :: (StatefulGen g m) =>
(Vector Double -> Double) -> (Vector Double -> Vector Double) ->
Vector Double -> Double -> g ->
(Vector Double, Double) -> m (Vector Double, Double)
malaKernel lpi glpi pre dt g = let
sdt = sqrt dt
spre = cmap sqrt pre
p = size pre
advance beta = beta + (scalar (0.5*dt))*pre*(glpi beta)
rprop beta g = do
zl <- (replicateM p . genContVar (normalDistr 0.0 1.0)) g
let z = fromList zl
return $ advance(beta) + (scalar sdt)*spre*z
dprop n o = let
ao = advance o
in sum $ (\i -> logDensity (normalDistr (ao!i)
((spre!i)*sdt)) (n!i)) <$> [0..(p-1)]
in mhKernel lpi rprop dprop g
See the full runnable script for further details.
Dex
Recall that Dex is differentiable, so we don’t need to provide gradients.
def mhKernel {s} (lpost: s -> Float) (rprop: s -> Key -> s) (dprop: s -> s -> Float)
(sll: (s & Float)) (k: Key) : (s & Float) =
(x0, ll0) = sll
[k1, k2] = split_key k
x = rprop x0 k1
ll = lpost x
a = ll - ll0 + (dprop x0 x) - (dprop x x0)
u = rand k2
select (log u < a) (x, ll) (x0, ll0)
def malaKernel {n} (lpi: (Fin n)=>Float -> Float)
(pre: (Fin n)=>Float) (dt: Float) :
((Fin n)=>Float & Float) -> Key -> ((Fin n)=>Float & Float) =
sdt = sqrt dt
spre = sqrt pre
glp = grad lpi
v = dt .* pre
vinv = map (\ x. 1.0/x) v
def advance (beta: (Fin n)=>Float) : (Fin n)=>Float =
beta + (0.5*dt) .* (pre*(glp beta))
def rprop (beta: (Fin n)=>Float) (k: Key) : (Fin n)=>Float =
(advance beta) + sdt .* (spre*(randn_vec k))
def dprop (new: (Fin n)=>Float) (old: (Fin n)=>Float) : Float =
ao = advance old
diff = new - ao
-0.5 * sum ((log v) + diff*diff*vinv)
mhKernel lpi rprop dprop
See the full runnable script for further details.
Next steps
MALA gives us an MCMC algorithm that exploits gradient information to generate "informed" M-H proposals. But it still has a rather "diffusive" character, making it difficult to tune in such a way that large moves are likely to be accepted in challenging high-dimensional situations.
The Langevin dynamics on which MALA is based can be interpreted as the (over-damped) stochastic dynamics of a particle moving in a potential energy field corresponding to minus the log posterior. It turns out that the corresponding deterministic dynamics can be exploited to generate proposals better able to make large moves while still having a high probability of acceptance. This is the idea behind Hamiltonian Monte Carlo (HMC), which we’ll look at next.
