Introduction
In the previous post I showed that it is possible to couple parallel tempered MCMC chains in order to improve mixing. Such methods can be used when the target of interest is a Bayesian posterior distribution that is difficult to sample. There are (at least) a couple of obvious ways that one can temper a Bayesian posterior distribution. Perhaps the most obvious way is a simple flattening, so that if
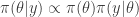
is the posterior distribution, then for ![t\in [0,1]](https://s0.wp.com/latex.php?latex=t%5Cin+%5B0%2C1%5D&bg=ffffff&fg=333333&s=0&c=20201002)
![\pi_t(\theta|y) \propto \pi(\theta|y)^t \propto [ \pi(\theta)\pi(y|\theta) ]^t.](https://s0.wp.com/latex.php?latex=%5Cpi_t%28%5Ctheta%7Cy%29+%5Cpropto+%5Cpi%28%5Ctheta%7Cy%29%5Et+%5Cpropto+%5B+%5Cpi%28%5Ctheta%29%5Cpi%28y%7C%5Ctheta%29+%5D%5Et.&bg=ffffff&fg=333333&s=0&c=20201002)
This corresponds with the tempering that is often used in statistical physics applications. We recover the posterior of interest for 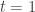
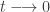
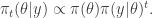
Here we again recover the posterior for 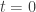
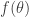


where, in our case, 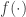
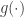
So, given a posterior distribution that is difficult to sample, choose a temperature schedule

and run a parallel tempering scheme as outlined in the previous post. The idea is that for small values of 
Marginal likelihood and normalising constants
The marginal likelihood of a Bayesian model is

This quantity is of interest for many reasons, including calculation of the Bayes factor between two competing models. Note that this quantity has several different names in different fields. In particular, it is often known as the evidence, due to its role in Bayes factors. It is also worth noting that it is the normalising constant of the Bayesian posterior distribution. Although it is very easy to describe and define, it is notoriously difficult to compute reliably for complex models.
The normalising constant is conceptually very easy to estimate. From the above integral representation, it is clear that
![\pi(y) = E_\pi [ \pi(y|\theta) ]](https://s0.wp.com/latex.php?latex=%5Cpi%28y%29+%3D+E_%5Cpi+%5B+%5Cpi%28y%7C%5Ctheta%29+%5D&bg=ffffff&fg=333333&s=0&c=20201002)
where the expectation is taken with respect to the prior. So, given samples from the prior, 

and this will be a consistent estimator of the true evidence under fairly mild regularity conditions. Unfortunately, in practice it is likely to be a very poor estimator if the posterior and prior are not very similar. Now, we could also use Bayes theorem to re-write the integral as an expectation with respect to the posterior, so we could then use samples from the posterior to estimate the evidence. This leads to the harmonic mean estimator of the evidence, which has been described as the worst Monte Carlo method ever! Now it turns out that there are many different ways one can construct estimators of the evidence using samples from the prior and the posterior, some of which are considerably better than the two I’ve outlined. This is the subject of the bridge sampling paper of Meng and Wong. However, the reality is that no method will work well if the prior and posterior are very different.
If we have tempered chains, then we have a sequence of chains targeting distributions which, by construction, are not too different, and so we can use the output from tempered chains in order to construct estimators of the evidence that are more numerically stable. If we call the evidence of the 
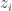



Now the 
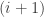

![\displaystyle \mbox{}\qquad = E_i\left[\pi(y|\theta)^{t_{i+1}-t_i}\right],](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmbox%7B%7D%5Cqquad+%3D+E_i%5Cleft%5B%5Cpi%28y%7C%5Ctheta%29%5E%7Bt_%7Bi%2B1%7D-t_i%7D%5Cright%5D%2C&bg=ffffff&fg=333333&s=0&c=20201002)
where the expectation is with respect to the
For numerical stability, in practice we compute the log of the evidence as
![\displaystyle \log\pi(y) = \sum_{i=0}^{N-1} \log\frac{z_{i+1}}{z_i} = \sum_{i=0}^{N-1} \log E_i\left[\pi(y|\theta)^{t_{i+1}-t_i}\right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Clog%5Cpi%28y%29+%3D+%5Csum_%7Bi%3D0%7D%5E%7BN-1%7D+%5Clog%5Cfrac%7Bz_%7Bi%2B1%7D%7D%7Bz_i%7D+%3D+%5Csum_%7Bi%3D0%7D%5E%7BN-1%7D+%5Clog+E_i%5Cleft%5B%5Cpi%28y%7C%5Ctheta%29%5E%7Bt_%7Bi%2B1%7D-t_i%7D%5Cright%5D&bg=ffffff&fg=333333&s=0&c=20201002)
![\displaystyle = \sum_{i=0}^{N-1} \log E_i\left[\exp\{(t_{i+1}-t_i)\log\pi(y|\theta)\}\right].\qquad(\dagger)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%3D+%5Csum_%7Bi%3D0%7D%5E%7BN-1%7D+%5Clog+E_i%5Cleft%5B%5Cexp%5C%7B%28t_%7Bi%2B1%7D-t_i%29%5Clog%5Cpi%28y%7C%5Ctheta%29%5C%7D%5Cright%5D.%5Cqquad%28%5Cdagger%29&bg=ffffff&fg=333333&s=0&c=20201002)
The above expression is exact, and is the obvious formula to use for computation. However, it is clear that if 

![\displaystyle \log\pi(y) \approx \sum_{i=0}^{N-1}(t_{i+1}-t_i)E_i\left[\log\pi(y|\theta)\right].](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Clog%5Cpi%28y%29+%5Capprox+%5Csum_%7Bi%3D0%7D%5E%7BN-1%7D%28t_%7Bi%2B1%7D-t_i%29E_i%5Cleft%5B%5Clog%5Cpi%28y%7C%5Ctheta%29%5Cright%5D.&bg=ffffff&fg=333333&s=0&c=20201002)
In the continuous limit, this gives rise to the well-known path sampling identity,
![\displaystyle \log\pi(y) = \int_0^1 E_t\left[\log\pi(y|\theta)\right]dt.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Clog%5Cpi%28y%29+%3D+%5Cint_0%5E1+E_t%5Cleft%5B%5Clog%5Cpi%28y%7C%5Ctheta%29%5Cright%5Ddt.&bg=ffffff&fg=333333&s=0&c=20201002)
So, an alternative approach to computing the evidence is to use the samples to approximately numerically integrate the above integral, say, using the trapezium rule. However, it isn’t completely clear (to me) that this is better than using 
Numerical illustration
We can illustrate these ideas using the simple double potential well example from the previous post. Now that example doesn’t really correspond to a Bayesian posterior, and is tempered directly, rather than as a power posterior, but essentially the same ideas follow for general parallel tempered distributions. In general, we can use the sample to estimate the ratio of the last and first normalising constants, 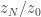
![\displaystyle \frac{z_{i+1}}{z_i} = E_i\left[\exp\{-(\gamma_{i+1}-\gamma_i)(x^2-1)^2\}\right].](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cfrac%7Bz_%7Bi%2B1%7D%7D%7Bz_i%7D+%3D+E_i%5Cleft%5B%5Cexp%5C%7B-%28%5Cgamma_%7Bi%2B1%7D-%5Cgamma_i%29%28x%5E2-1%29%5E2%5C%7D%5Cright%5D.&bg=ffffff&fg=333333&s=0&c=20201002)
A Monte Carlo estimate of each of these terms is formed using the samples from the 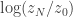
U=function(gam,x)
{
gam*(x*x-1)*(x*x-1)
}
temps=2^(0:3)
iters=1e5
chains=function(pot=U, tune=0.1, init=1)
{
x=rep(init,length(temps))
xmat=matrix(0,iters,length(temps))
for (i in 1:iters) {
can=x+rnorm(length(temps),0,tune)
logA=unlist(Map(pot,temps,x))-unlist(Map(pot,temps,can))
accept=(log(runif(length(temps)))<logA)
x[accept]=can[accept]
swap=sample(1:length(temps),2)
logA=pot(temps[swap[1]],x[swap[1]])+pot(temps[swap[2]],x[swap[2]])-
pot(temps[swap[1]],x[swap[2]])-pot(temps[swap[2]],x[swap[1]])
if (log(runif(1))<logA)
x[swap]=rev(x[swap])
xmat[i,]=x
}
colnames(xmat)=paste("gamma=",temps,sep="")
xmat
}
mat=chains()
mat=mat[,1:(length(temps)-1)]
diffs=diff(temps)
mat=(mat*mat-1)^2
mat=-t(diffs*t(mat))
mat=exp(mat)
logEvidence=sum(log(colMeans(mat)))
message(paste("The log of the ratio of the last and first normalising constants is",logEvidence))
It turns out that these double well potential densities are tractable, and so the normalising constants can be computed exactly. So, with a little help from Wolfram Alpha, I compute log of the ratio of the last and first normalising constants to be approximately -1.12. Hopefully the above script will output something a bit like that…
References
- Meng, Xiao-Li, and Wing Hung Wong. “Simulating ratios of normalizing constants via a simple identity: a theoretical exploration.” Statistica Sinica 6.4 (1996): 831-860.
- Gelman, Andrew, and Xiao-Li Meng. “Simulating normalizing constants: From importance sampling to bridge sampling to path sampling.” Statistical Science (1998): 163-185.
- Friel, Nial, and Anthony N. Pettitt. “Marginal likelihood estimation via power posteriors.” Journal of the Royal Statistical Society: Series B (Statistical Methodology) 70.3 (2008): 589-607.
- Friel, Nial, and Jason Wyse. “Estimating the evidence–a review.” Statistica Neerlandica 66.3 (2012): 288-308.

2 thoughts on “Marginal likelihood from tempered Bayesian posteriors”