Introduction
Regular readers of this blog will know that in April 2010 I published a short post showing how a trivial bivariate Gibbs sampler could be implemented in the four languages that I use most often these days (R, python, C, Java), and I discussed relative timings, and how one might start to think about trading off development time against execution time for more complex MCMC algorithms. I actually wrote the post very quickly one night while I was stuck in a hotel room in Seattle – I didn’t give much thought to it, and the main purpose was to provide simple illustrative examples of simple Monte Carlo codes using non-uniform random number generators in the different languages, as a starting point for someone thinking of switching languages (say, from R to Java or C, for efficiency reasons). It wasn’t meant to be very deep or provocative, or to start any language wars. Suffice to say that this post has had many more hits than all of my other posts combined, is still my most popular post, and still attracts comments and spawns other posts to this day. Several people have requested that I re-do the post more carefully, to include actual timings, and to include a few additional optimisations. Hence this post. For reference, the original post is here. A post about it from the python community is here, and a recent post about using Rcpp and inlined C++ code to speed up the R version is here.
The sampler
So, the basic idea was to construct a Gibbs sampler for the bivariate distribution

with unknown normalising constant 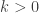

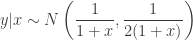
Note the factor of two in the variance of the full conditional for 
Implementations
R
Let’s start with R again. The slightly modified version of the code from the old post is given below
gibbs=function(N,thin)
{
mat=matrix(0,ncol=3,nrow=N)
mat[,1]=1:N
x=0
y=0
for (i in 1:N) {
for (j in 1:thin) {
x=rgamma(1,3,y*y+4)
y=rnorm(1,1/(x+1),1/sqrt(2*x+2))
}
mat[i,2:3]=c(x,y)
}
mat=data.frame(mat)
names(mat)=c("Iter","x","y")
mat
}
writegibbs=function(N=50000,thin=1000)
{
mat=gibbs(N,thin)
write.table(mat,"data.tab",row.names=FALSE)
}
writegibbs()
I’ve just corrected the full conditional, and I’ve increased the sample size and thinning to 50k and 1k, respectively, to allow for more accurate timings (of the faster languages). This code can be run from the (Linux) command line with something like:
time Rscript gibbs.R
I discuss timings in detail towards the end of the post, but this code is slow, taking over 7 minutes on my (very fast) laptop. Now, the above code is typical of the way code is often structured in R – doing as much as possible in memory, and writing to disk only if necessary. However, this can be a bad idea with large MCMC codes, and is less natural in other languages, anyway, so below is an alternative version of the code, written in more of a scripting language style.
gibbs=function(N,thin)
{
x=0
y=0
cat(paste("Iter","x","y","\n"))
for (i in 1:N) {
for (j in 1:thin) {
x=rgamma(1,3,y*y+4)
y=rnorm(1,1/(x+1),1/sqrt(2*x+2))
}
cat(paste(i,x,y,"\n"))
}
}
gibbs(50000,1000)
This can be run with a command like
time Rscript gibbs-script.R > data.tab
This code actually turns out to be a slightly slower than the in-memory version for this simple example, but for larger problems I would not expect that to be the case. I always analyse MCMC output using R, whatever language I use for running the algorithm, so for completeness, here is a bit of code to load up the data file, do some plots and compute summary statistics.
fun=function(x,y)
{
x*x*exp(-x*y*y-y*y+2*y-4*x)
}
compare<-function(file="data.tab")
{
mat=read.table(file,header=TRUE)
op=par(mfrow=c(2,1))
x=seq(0,3,0.1)
y=seq(-1,3,0.1)
z=outer(x,y,fun)
contour(x,y,z,main="Contours of actual (unnormalised) distribution")
require(KernSmooth)
fit=bkde2D(as.matrix(mat[,2:3]),c(0.1,0.1))
contour(fit$x1,fit$x2,fit$fhat,main="Contours of empirical distribution")
par(op)
print(summary(mat[,2:3]))
}
compare()
Python
Another language I use a lot is Python. I don’t want to start any language wars, but I personally find python to be a better designed language than R, and generally much nicer for the development of large programs. A python script for this problem is given below
import random,math
def gibbs(N=50000,thin=1000):
x=0
y=0
print "Iter x y"
for i in range(N):
for j in range(thin):
x=random.gammavariate(3,1.0/(y*y+4))
y=random.gauss(1.0/(x+1),1.0/math.sqrt(2*x+2))
print i,x,y
gibbs()
It can be run with a command like
time python gibbs.py > data.tab
This code turns out to be noticeably faster than the R versions, taking around 4 minutes on my laptop (again, detailed timing information below). However, there is a project for python known as the PyPy project, which is concerned with compiling regular python code to very fast byte-code, giving significant speed-ups on certain problems. For this post, I downloaded and install version 1.5 of the 64-bit linux version of PyPy. Once installed, I can run the above code with the command
time pypy gibbs.py > data.tab
To my astonishment, this “just worked”, and gave very impressive speed-up over regular python, running in around 30 seconds. This actually makes python a much more realistic prospect for the development of MCMC codes than I imagined. However, I need to understand the limitations of PyPy better – for example, why doesn’t everyone always use PyPy for everything?! It certainly seems to make python look like a very good option for prototyping MCMC codes.
C
Traditionally, I have mainly written MCMC codes in C, using the GSL. C is a fast, efficient, statically typed language, which compiles to native code. In many ways it represents the “gold standard” for speed. So, here is the C code for this problem.
#include <stdio.h>
#include <math.h>
#include <stdlib.h>
#include <gsl/gsl_rng.h>
#include <gsl/gsl_randist.h>
void main()
{
int N=50000;
int thin=1000;
int i,j;
gsl_rng *r = gsl_rng_alloc(gsl_rng_mt19937);
double x=0;
double y=0;
printf("Iter x y\n");
for (i=0;i<N;i++) {
for (j=0;j<thin;j++) {
x=gsl_ran_gamma(r,3.0,1.0/(y*y+4));
y=1.0/(x+1)+gsl_ran_gaussian(r,1.0/sqrt(2*x+2));
}
printf("%d %f %f\n",i,x,y);
}
}
It can be compiled and run with command like
gcc -O4 gibbs.c -lgsl -lgslcblas -lm -o gibbs time ./gibbs > datac.tab
This runs faster than anything else I consider in this post, taking around 8 seconds.
Java
I’ve recently been experimenting with Java for MCMC codes, in conjunction with Parallel COLT. Java is a statically typed object-oriented (O-O) language, but is usually compiled to byte-code to run on a virtual machine (known as the JVM). Java compilers and virtual machines are very fast these days, giving “close to C” performance, but with a nicer programming language, and advantages associated with virtual machines. Portability is a huge advantage of Java. For example, I can easily get my Java code to run on almost any University Condor pool, on both Windows and Linux clusters – they all have a recent JVM installed, and I can easily bundle any required libraries with my code. Suffice to say that getting GSL/C code to run on generic Condor pools is typically much less straightforward. Here is the Java code:
import java.util.*;
import cern.jet.random.tdouble.*;
import cern.jet.random.tdouble.engine.*;
class Gibbs
{
public static void main(String[] arg)
{
int N=50000;
int thin=1000;
DoubleRandomEngine rngEngine=new DoubleMersenneTwister(new Date());
Normal rngN=new Normal(0.0,1.0,rngEngine);
Gamma rngG=new Gamma(1.0,1.0,rngEngine);
double x=0;
double y=0;
System.out.println("Iter x y");
for (int i=0;i<N;i++) {
for (int j=0;j<thin;j++) {
x=rngG.nextDouble(3.0,y*y+4);
y=rngN.nextDouble(1.0/(x+1),1.0/Math.sqrt(2*x+2));
}
System.out.println(i+" "+x+" "+y);
}
}
}
It can be compiled and run with
javac Gibbs.java time java Gibbs > data.tab
This takes around 11.6s seconds on my laptop. This is well within a factor of 2 of the C version, and around 3 times faster than even the PyPy python version. It is around 40 times faster than R. Java looks like a good choice for implementing MCMC codes that would be messy to implement in C, or that need to run places where it would be fiddly to get native codes to run.
Scala
Another language I’ve been taking some interest in recently is Scala. Scala is a statically typed O-O/functional language which compiles to byte-code that runs on the JVM. Since it uses Java technology, it can seamlessly integrate with Java libraries, and can run anywhere that Java code can run. It is a much nicer language to program in than Java, and feels more like a dynamic language such as python. In fact, it is almost as nice to program in as python (and in some ways nicer), and will run in a lot more places than PyPy python code. Here is the scala code (which calls Parallel COLT for random number generation):
object GibbsSc {
import cern.jet.random.tdouble.engine.DoubleMersenneTwister
import cern.jet.random.tdouble.Normal
import cern.jet.random.tdouble.Gamma
import Math.sqrt
import java.util.Date
def main(args: Array[String]) {
val N=50000
val thin=1000
val rngEngine=new DoubleMersenneTwister(new Date)
val rngN=new Normal(0.0,1.0,rngEngine)
val rngG=new Gamma(1.0,1.0,rngEngine)
var x=0.0
var y=0.0
println("Iter x y")
for (i <- 0 until N) {
for (j <- 0 until thin) {
x=rngG.nextDouble(3.0,y*y+4)
y=rngN.nextDouble(1.0/(x+1),1.0/sqrt(2*x+2))
}
println(i+" "+x+" "+y)
}
}
}
It can be compiled and run with
scalac GibbsSc.scala time scala GibbsSc > data.tab
This code takes around 11.8s on my laptop – almost as fast as the Java code! So, on the basis of this very simple and superficial example, it looks like scala may offer the best of all worlds – a nice, elegant, terse programming language, functional and O-O programming styles, the safety of static typing, the ability to call on Java libraries, great speed and efficiency, and the portability of Java! Very interesting.
Groovy
James Durbin has kindly sent me a Groovy version of the code, which he has also discussed in his own blog post. Groovy is a dynamic O-O language for the JVM, which, like Scala, can integrate nicely with Java applications. It isn’t a language I have examined closely, but it seems quite nice. The code is given below:
import cern.jet.random.tdouble.engine.*;
import cern.jet.random.tdouble.*;
N=50000;
thin=1000;
rngEngine= new DoubleMersenneTwister(new Date());
rngN=new Normal(0.0,1.0,rngEngine);
rngG=new Gamma(1.0,1.0,rngEngine);
x=0.0;
y=0.0;
println("Iter x y");
for(i in 1..N){
for(j in 1..thin){
x=rngG.nextDouble(3.0,y*y+4);
y=rngN.nextDouble(1.0/(x+1),1.0/Math.sqrt(2*x+2));
}
println("$i $x $y");
}
It can be run with a command like:
time groovy Gibbs.gv > data.tab
Again, rather amazingly, this code runs in around 35 seconds – very similar to the speed of PyPy. This makes Groovy also seem like a potential very attractive environment for prototyping MCMC codes, especially if I’m thinking about ultimately porting to Java.
Timings
The laptop I’m running everything on is a Dell Precision M4500 with an Intel i7 Quad core (x940@2.13Ghz) CPU, running the 64-bit version of Ubuntu 11.04. I’m running stuff from the Ubuntu (Unity) desktop, and running several terminals and applications, but the machine is not loaded at the time each job runs. I’m running each job 3 times and taking the arithmetic mean real elapsed time. All timings are in seconds.
| R 2.12.1 (in memory) | 435.0 |
| R 2.12.1 (script) | 450.2 |
| Python 2.7.1+ | 233.5 |
| PyPy 1.5 | 32.2 |
| Groovy 1.7.4 | 35.4 |
| Java 1.6.0 | 11.6 |
| Scala 2.7.7 | 11.8 |
| C (gcc 4.5.2) | 8.1 |
If we look at speed-up relative to the R code (in-memory version), we get:
| R (in memory) | 1.00 |
| R (script) | 0.97 |
| Python | 1.86 |
| PyPy | 13.51 |
| Groovy | 12.3 |
| Java | 37.50 |
| Scala | 36.86 |
| C | 53.70 |
Alternatively, we can look at slow-down relative to the C version, to get:
| R (in memory) | 53.7 |
| R (script) | 55.6 |
| Python | 28.8 |
| PyPy | 4.0 |
| Groovy | 4.4 |
| Java | 1.4 |
| Scala | 1.5 |
| C | 1.0 |
Discussion
The findings here are generally consistent with those of the old post, but consideration of PyPy, Groovy and Scala does throw up some new issues. I was pretty stunned by PyPy. First, I didn’t expect that it would “just work” – I thought I would either have to spend time messing around with my configuration settings, or possibly even have to modify my code slightly. Nope. Running python code with pypy appears to be more than 10 times faster than R, and only 4 times slower than C. I find it quite amazing that it is possible to get python code to run just 4 times slower than C, and if that is indicative of more substantial examples, it really does open up the possibility of using python for “real” problems, although library coverage is currently a problem. It certainly solves my “prototyping problem”. I often like to prototype algorithms in very high level dynamic languages like R and python before porting to a more efficient language. However, I have found that this doesn’t always work well with complex MCMC codes, as they just run too slowly in the dynamic languages to develop, test and debug conveniently. But it looks now as though PyPy should be fast enough at least for prototyping purposes, and may even be fast enough for production code in some circumstances. But then again, exactly the same goes for Groovy, which runs on the JVM, and can access any existing Java library… I haven’t yet looked into Groovy in detail, but it appears that it could be a very nice language for prototyping algorithms that I intend to port to Java.
The results also confirm my previous findings that Java is now “fast enough” that one shouldn’t worry too much about the difference in speed between it and native code written in C (or C++). The Java language is much nicer than C or C++, and the JVM platform is very attractive in many situations. However, the Scala results were also very surprising for me. Scala is a really elegant language (certainly on a par with python), comes with all of the advantages of Java, and appears to be almost as fast as Java. I’m really struggling to come up with reasons not to use Scala for everything!
Speeding up R
MCMC codes are used by a range of different scientists for a range of different problems. However, they are very (most?) often used by Bayesian statisticians who use the algorithms to target a Bayesian posterior distribution. For various (good) reasons, many statisticians are heavily invested in R, like to use R as much as possible, and do as much as possible from within the R environment. These results show why R is not a good language in which to implement MCMC algorithms, so what is an R-dependent statistician supposed to do? One possibility would be to byte-code compile R code in an analogous way to python and pypy. The very latest versions of R support such functionality, but the post by Dirk Eddelbuettel suggests that the current version of cmpfun will only give a 40% speedup on this problem, which is still slower than regular python code. Short of a dramatic improvement in this technology, the only way forward seems to be to extend R using code from another language. It is easy to extend R using C, C++ and Java. I have shown in previous posts how to do this using Java and using C, and the recent post by Dirk shows how to extend using C++. Although interesting, this doesn’t really have much bearing on the current discussion. If you extend using Java you get Java-like speedups, and if you extend using C you get C-like speedups. However, in case people are interested, I intend to gather up these examples into one post and include detailed timing information in a subsequent post.

Have you tried using Bugs for MCMC? Seems like many textbooks that use R also use Bugs to improve performance on MCMC.
And have you tried using REvolution instead of just R? REvolution can take advantage of multithreading on Intels:
http://blog.revolutionanalytics.com/2010/06/performance-benefits-of-multithreaded-r.html
Yes, Bugs and OpenBugs can both be useful for relatively simple problems. As can JAGS and rjags, which I tend to use in preference. I keep meaning to do a post on JAGS and rjags, but haven’t yet got around to it. But there are many problems where these off-the-shelf solutions are not adequate.
Regarding multithreading and R, you don’t need to use Revolution R to exploit multiple cores. Multicore R stuff is another post on my list… But you don’t get even 4x speedup on your average quad-core machine, and you can multithread Java and Scala code, too…
If you thought PyPy 1.5 was good, wait until you see what we have cooking for our next release 🙂 On my system our current trunk was about 33% faster than 1.5.
Very interesting comparison. It’s rare to find real-world code that is implemented across different languages.
Thanks for the kind words for PyPy (I’m one of the devs). A reason for not using PyPy everywhere is that it does not support all extension modules that work with CPython.
Yes, I guessed that module coverage would be an issue. Do you happen to know what the coverage of numpy/scipy is like?
Not good yet. Both of them are not supported so far. However, there are efforts underway to implement numpy together with good JIT support for numpy arrays. scipy will have to come after that. Around end of this year things might look much better in this regard. These modules are basically most often requested, so there’s a big incentive to work on them :-).
While we’re at it, here’s the mex version for Matlab: http://xcorr.net/2011/07/16/gibbs-sampler-in-matlab-using-mexme/. Conclusion: mex has very little overhead.
Hi Darren,
Thanks for the post! It’s nice to see someone implement some scientific computation code across multiple languages to give a real-world speed comparison.
I just wanted to note that Scala and Java, though basically equivalent in speed here, should not necessarily be considered on the same footing in practice due to the simplicity of your code. That’s not to say that if you throw something more complex at Scala it will massively falter, but I wouldn’t expect it to be 1-to-1 with Java in all situations.
That said, I very much appreciate this post!
Very true, and that goes for all of the languages. All that these comparisons really tell us about is speed of basic random number generation and loops. That is interesting in itself, but not the whole story.
Interesting post!
Here is a Matlab version:
%///////////////////////////////////////////////////
function gibbs(n,thin)
x=0;
y=0;
for i=1:n
gammarands=randg(3,thin,1);
normrands=randn(thin,1);
for j=1:thin
x=(y^2+4)*gammarands(j);
y=1/(1+x)+normrands(j)/sqrt(2*x+2);
end
end
end
tic
gibbs(5e4,1e3);
toc
%///////////////////////////////////////////////////
On my pc this runs in under 10 seconds (due to JIT compilation).
Thanks. Of course, you have used a couple of tricks there which I deliberately didn’t include in my examples, in order to try and be “fair” to the various languages. Also, I don’t think you can just ignore the issue of recording the output in this example. The Matlab examples are interesting, but obviously Matlab isn’t free software, and can be difficult to use in distributed and cloud computing environments.
Update: 29/7/11. James Durbin has sent me a Groovy version of the code. Rather than trying to fudge this into a comment, or write another post, I’ve just edited the post to include the Groovy example. It looks very interesting!
For those considering which language to implement their next scientific project in, I also recommend Language Shootout ( http://shootout.alioth.debian.org/ ). It’s tests are based more on numerical computation that random number simulation, but it gives a clean, detailed view of how languages compare with that respect.
With pypy 1.7 I’m seeing more like a factor of 2 difference between C and pypy. Impressive.
$ time ./wilk > datac.tab
real 0m25.026s
user 0m23.577s
sys 0m0.140s
$ time pypy wilk.py > data_pypy.tab
real 0m46.510s
user 0m44.591s
sys 0m0.212s
Hi,
I do a lot of sampling using C and noticed you used the Mersenne -Twister random number generator.
I just thought I’d point out that, in at least the most common applications, this algorithm is great for producing random numbers with a huge period. But with the huge period comes a sacrifice at computational cost. I personally use the gsl_rng_taus2 algorithm. It has a smaller period (but not so small that you will ever see these effects in practice) but it’s much faster at producing random numbers.
As a final note, the default algorithm for producing Gaussian random numbers in GSL is the Box-Müller algorithm, which is great. I use the Ziggurat algorithm, whose average behaviour is cheaper than that of Box-Müller and produces results almost as good.
Maybe some day I’ll write a comparison using those two methods in C.
Anyway, your article was a nice read. Thanks 🙂
You’re right about the MT being expensive – I know that Marsaglia is not a fan of it, but it is a “safe” choice, and it is implemented similarly in the GSL and Parallel COLT, which was important for “fair” comparison between Java and C. Same comment regarding use of Box-Muller for Gaussians, though I think PC actually caches the second variate and GSL doesn’t, which isn’t totally fair now I come to think of it…
I totally agree with you. You did the right thing by trying to use the same methods and RNGs in each case, of course. There’s a nice article on RNGs by David Jones at UCL called ‘Good Practice in (Pseudo) Random Number Generation for Bioinformatics Applications’.
For me, the take-home message (and probably for the wider, less programmy, audience) of Python and PyPy is nice.
Thanks again for an interesting article.
what about python 3.x implementation? python 2.x creates a list when range(N) is called, so python 3.x might be bit faster…
Python 2.x has that functionality, too. Just use xrange instead of range.
I’ve recently been interested in coding expensive algorithms in different languages and this was a very interesting post. I’ve coded up the R, Python, C (in C++) and Java programs on Max Os X Snow Leopard and can report similar timings.
I am still, however, a little skeptical about Java. One of the largest and trickiest operations in an MCMC or any large Bayesian calculation can be the construction, multiplication and decomposition of large matrices. Colt, at least, is very slow at simple matrix operations in comparison to R, Python and C. For example the guy here: http://stackoverflow.com/questions/529457/performance-of-java-matrix-math-libraries tries multiplying a 3000×3000 matrix with itself in C++, R, Python and Java using Colt and parallel colt (and some other languages and packages). He reported that whilst the first three took around 4 seconds, Colt took 150!
Have you worked with a Java package that can match the efficiency of these other languages for matrix operations?
If large matrix computations really are your bottleneck, then you will need to use an optimised native BLAS. As mentioned in the SO thread you point at, using JBLAS with Java is then just as fast as other platforms which call out to the BLAS (though I’ve not used it). But calling out to native code removes some of the attraction of Java, and if that really is your bottleneck, you are probably fine with Python or R anyway.
Well the bottleneck in R is usually the loop which contains matrix operations. Suppose, for example, you have an MCMC for a Gaussian process with a prior distribution on the correlation lengths. To evaluate the likelihood for any proposed new correlation lengths will require the construction and cholesky decomposition of a possibly large variance matrix. So the matrix bit is probably fast, but it happens inside a big loop, which of course is slow in R. The pypy package looks exciting but I havn’t tested to see if it is compatible with packages that allow for fast cholesky decompositions in python for example.
Yes – these are precisely the kinds of problems that first drove me to C and subsequently to Java. I think you should try Java and see how you get on! My guess is that it will be fine, and that using JBLAS will buy you performance over PColt, but hurt you in portability. The trouble with pypy (if I understand correctly) is that it can’t easily call out to native code, so the actual matrix operations will be slower than calling out to an optimised native BLAS…
I have repeated this excellent experiment on a Macbook pro 3.06GHz Inter Core 2 Duo with 8GB memory using Mac Os X 10.6.8 and included a version with COLT replacing ParallelColt for Java (as it is slightly better documented). I also used C++ instead of C. I thought it would be interesting to share my findings for two reasons. 1. It is interesting to see how the times compare (between languages) using a Mac and 2. Installing libraries and packages for coding on a Mac is never straightforward in my experience, so I wanted to check and report that it can be done (though with some effort!). The numbers are as follows:
Language Time (s)
R (2.13.1) 682
Python(2.6.1) 338
pypy (1.9) 26.4
Java (colt) 15.7
Java (parallel) 12.4
C++ (using g++) 7.1
It appears as though the Mac-version of this experiment has R much slower than the original (by nearly 3 minutes!), even though timings for the other languages are roughly the same if not slightly faster (possibly due to version updates).
Dear Darren,
Thank you for your carefully discussed time comparison. I do a lot of MCMC, mostly in R. When I really have to, I write my C functions which I then call from R. I had been thinking about Python for some time and your post prompted me to give it a try. I wanted to confirm your timing results on a slightly more complicated model, so I decided to use a Normal regression model, in which the regressors are a factor with four levels and a numerical covariate. I have timed a fairly simple Gibbs sampler both in R and in Python, but to my surprise the outcome was the opposite of what I would have expected – and of what you reported in your post!
Here are the times.
gpetris$ time python firstGibbs.py > gibbsPy.out
real 2m35.320s
user 2m35.071s
sys 0m0.214s
gpetris$ time Rscript firstGibbs.R > gibbsR.out
real 0m27.881s
user 0m27.444s
sys 0m0.406s
Do you have any explanation for that?
The code for both versions, with the data set used in the example, can be found at definetti.uark.edu/~gpetris/Gibbs.
Thank you for any insight you can provide!
Best,
Giovanni Petris
The Python code does not show what is possible in CPython. For one printing results slows it down. ‘Import y’ and ‘y.x.’ is also slower than ‘from y import x’. And finally, ‘numpy.random’ is much quicker than ‘random’.
On my computer:
Original function: 178.540799999
Original function without prints: 169.056849999
Numpy for random numbers, no prints: 44.8219899988
Numpypy does not have random implemented yet, so I couldn’t test it in PyPy.
The fastest code is:
from numpy.random import gamma, randn
from math import sqrt
def gibbs(N=50000,thin=1000):
x=0
y=0
res=[]
for i in xrange(N):
for j in xrange(thin):
x=gamma(3,1.0/(y**2+4))
y=randn()/sqrt(2*x+2)+1.0/(x+1)
res.append([i,x,y])
res.append([i,x,y])
return res
I just tested this example with Common Lisp (SBCL 1.1.2 on Debian squeeze), with cl-randist (see https://github.com/lvaruzza/cl-randist/ and http://www.cliki.net/cl-randist), which is a pure CL implemention of random number distributions, supposedly based on GSL. With your same code, but with the printing removed, your C version clocks between 24 and 25 secs on my machine. The CL version is at around 18 sec. It is worth commenting (maybe someone has already done so) that these aren’t really fair comparisons, since the computation is dominated by the random distribution functions, and different languages probably use different algorithms, which might vary significantly in efficiency. A fair comparison might be to implement all these distribution functions using the same algorithm and in the host language. Of course, if this was done systematically, languages like Python would fare even worse in the comparison, as I bet the Python functions are written in C. I include the CL code below.
(defun lgibbs (N thin)
(declare (fixnum N thin))
(declare (optimize (speed 3) (debug 0) (safety 1)))
(let ((x 0.0) (y 0.0) (*print-pretty* nil))
(declare ((double-float 0.0 *) x))
(declare (double-float y))
;;(print “Iter x y”)
(dotimes (i N)
(dotimes (j thin)
(declare (fixnum i j))
(setf x (cl-randist::random-gamma 3.0 (/ 1.0 (+ (* y y) 4))))
(setf y (cl-randist::random-normal (/ 1.0 (+ x 1.0)) (/ 1.0 (sqrt (+ (* 2 x) 2))))))
;;(format t “~a ~a ~a~%” i x y)
)))
(defun main ()
(lgibbs 50000 1000))
Recently I found shedskin (http://code.google.com/p/shedskin/) a nice C++ compiler for Python. Might be usefuel for math code with standard libs ( 10x faster as py-code).
Was playing around in a notebook and using numpy instead of random seems to speed things up quite a bit (in Python): http://nbviewer.ipython.org/gist/anonymous/49a489f5e8c05796c0a4 … The random module is pretty bare bones. Also a trivial hack with cython goes pretty far on my machine at least.
Reblogged this on Wikia.
I came across your blog when I was looking for a code implementation to aid my understanding so thanks. I have implemented similar code in fortran for a prog on boltzman machines. I understand the code but I don’t understand where the initial equation of x y came from, why you chose gamma/gaussian distributions – could you choose others? – also how does the original equation provide parameters alpha and beta from the f(x,y) eqn. Finally, how do we know that the C Java, Python, R eqns implement gamma and gaussian distribution equivalently – which is correct ?
thanks
Steve
The post isn’t really meant to be an introduction to MCMC, but to instead provide some code examples. It sounds like you should read an introduction to MCMC – I do have some old lecture notes on this: https://www.staff.ncl.ac.uk/d.j.wilkinson/teaching/mas451/notes.pdf – which you might find useful. In short, I picked the f() that I did because I knew it would have Gaussian and gamma full-conditionals, and the constants are determined by the form of f().
There are lots of ways to test that random number generators are working correctly and are equivalent. eg. you can test the mean and variance of a large number of samples, quantiles of the empirical distributions, etc.
Thanks Darren
That’s some of the background info I had been looking for having previously treated some of the equations as black box solutions.
Just to clarify about equivalence of generators, I’m using Intel’s Fortran compiler and MKL library, they have a slightly different implementation to GNU for example. eg see bottom of https://software.intel.com/en-us/node/521882 vs GNU GSL. Also MKL implementation returns a vector as opposed to a singular value.
I looked at some of the other implementations to verify what algorithm they were calculating (I found ifort was x2.5 times faster on the same backpropagation code with like for like O3 optimization in comparison to gnu gfortran)
For info my Fortran implementation was quite slow but this was probably because I was setting the MKL gamma vector length to 1 to calculate x then setting the vector length in the gaussian distribution to 1 in order to calc y. If Just use the two distributions to calculate 10 million unrelated samples it is extremely fast but unfortunately there is no cross relation between x and y. On my machine your C example came in at 7.9 s
Just for curiosity I plotted a sample of the calculated x , y values in excel and that was quite informative
regards
Steve
For me (old school, active scientific programmer) it’s puzzling that C is still being used, and that other languages are being considered, even though they’re even more confusing and/or slower. Obviously, I’m not trying to impress generation X, Y (or newer) but please try to read on anyway 😐
For serious number crunching on supercomps, the first and the best language ever (Fortran) is recommended. Why Fortran90 not C? C/C++ is glorified assebler, not a numerical simulation languange, and MCMC is no exception here. Fortran is significantly higher level language than C, which doesn’t even have a short way to express “2 to the power of 2” as 2^2 or 2**2 as in other languages. C and especially C++ confuses some of the compiler’s attempts to auto-optimize (multithread and vectorize, both essential for properly using your processors). It confuses the programmers even more. That’s why we don’t even teach it to undergrads anymore (Python’s easier for then to grasp). Unless you write operating systems, hack, or do GPU programming (which I do, clenching my teeth, in C-CUDA sometimes), you can forget about that language. It is never faster than Fortran, only much more wordy (programs are bulky), more prone to memory leakage, segmentation faults and all that. I don’t C any advantage over Fortran for large-scale simulations.
IDL or python of many other choices are OK to visualize results or
write wrappers for the core routines compiled by ifort (that’s Intel compiler –
you’ll need it; the code is usually 2+ times faster than under gnu fortran, when run on Intel cpus, and of course you need ifort if you build you own clusters with XEON PHI, a very cool coprocessor!).
I’ll bet Julia is worth a consideration here now too.
Fortran would be cool to see too, but I appreciate any language comparison @Pawel. Often your environment, maybe development group, are dictating the tools you use. What if I wanted to implement this on some embedded device? I definitely wouldn’t use Fortran and would probably use C.
First of all thanks for the nice post. I would like to also recommend to extend the post by adding python3 which has the ability to define statically typed variables and see how that changes. Finally you should also include nim which provides a very nice interface to code in abstract level like in python and at the same time speeds close or similar to c.